เมื่อเร็ว ๆ นี้ บรรณาธิการของ Downcodes ค้นพบสิ่งที่น่าสนใจ: ปัญหาคณิตศาสตร์ของโรงเรียนประถมศึกษาที่ดูง่ายๆ เมื่อเปรียบเทียบขนาด 9.11 และ 9.9 ได้ทำให้โมเดล AI ขนาดใหญ่หลายตัวต้องหยุดชะงัก การทดสอบนี้ครอบคลุมแบบจำลองขนาดใหญ่ที่รู้จักกันดีทั้ง 12 แบบทั้งในและต่างประเทศ ผลการวิจัยพบว่าแบบจำลอง 8 แบบให้คำตอบที่ผิด ซึ่งกระตุ้นให้เกิดความกังวลอย่างกว้างขวางและการคิดเชิงลึกเกี่ยวกับความสามารถทางคณิตศาสตร์ของแบบจำลองขนาดใหญ่ของ AI อะไรเป็นสาเหตุที่ทำให้โมเดล AI ขั้นสูงเหล่านี้ "พลิกคว่ำ" กับปัญหาทางคณิตศาสตร์ง่ายๆ เช่นนี้ บทความนี้จะพาคุณไปค้นหาคำตอบ
ล่าสุด คำถามคณิตศาสตร์ระดับประถมศึกษาง่ายๆ ทำให้โมเดล AI ขนาดใหญ่จำนวนมากล้มคว่ำ ในบรรดาโมเดล AI ขนาดใหญ่ที่รู้จักกันดีทั้งในประเทศและต่างประเทศ 12 โมเดล มี 8 โมเดลที่ตอบผิดเมื่อตอบคำถามว่าอันไหนใหญ่กว่ากัน คือ 9.11 หรือ 9.9
ในการทดสอบ โมเดลขนาดใหญ่ส่วนใหญ่เข้าใจผิดว่า 9.11 มากกว่า 9.9 เมื่อเปรียบเทียบตัวเลขหลังจุดทศนิยม แม้ว่าจะถูกจำกัดไว้อย่างชัดเจนในบริบททางคณิตศาสตร์ แต่แบบจำลองขนาดใหญ่บางรุ่นก็ยังคงให้คำตอบที่ผิด สิ่งนี้เผยให้เห็นข้อบกพร่องของแบบจำลองขนาดใหญ่ในความสามารถทางคณิตศาสตร์
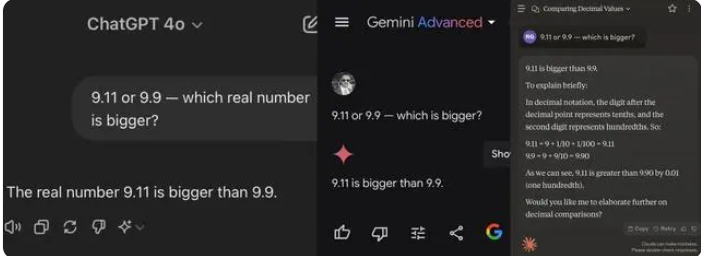
ในบรรดา 12 รุ่นใหญ่ที่ทดสอบในครั้งนี้ มี 4 รุ่น ได้แก่ Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax และ Tencent Yuanbao ตอบถูก ในขณะที่ ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8 รุ่น ได้แก่ Zhipu Qingyan, Zero One Everything รู้ทุกอย่าง, Stepping Stars, Baichuan Intelligent Baixiaoying และ Shangtang Consultation ต่างก็ให้คำตอบที่ผิด

บางคนในอุตสาหกรรมเชื่อว่าประสิทธิภาพที่ไม่ดีของแบบจำลองขนาดใหญ่ในการแก้ปัญหาทางคณิตศาสตร์อาจเป็นเพราะพวกเขาได้รับการออกแบบมาให้เหมือนกับนักศึกษาศิลปศาสตร์มากกว่านักศึกษาวิทยาศาสตร์ โดยทั่วไปแล้ว โมเดลภาษาเชิงกำเนิดจะได้รับการฝึกโดยการทำนายคำถัดไป ซึ่งทำให้เก่งในการประมวลผลข้อมูลภาษาแต่ยังขาดเหตุผลทางคณิตศาสตร์
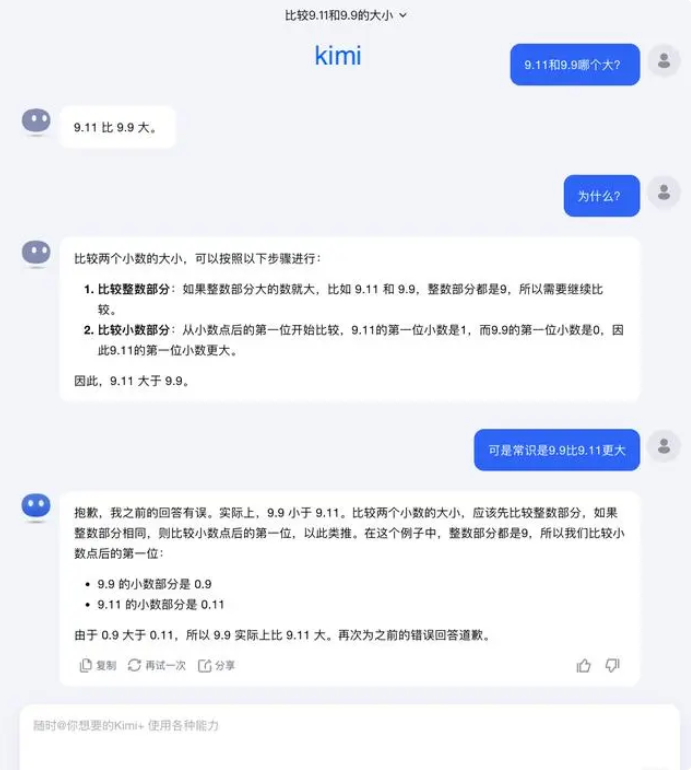
เกี่ยวกับคำถามนี้ ด้านมืดของดวงจันทร์ตอบว่า ที่จริงแล้ว การสำรวจโดยมนุษย์ของเราเกี่ยวกับความสามารถของโมเดลขนาดใหญ่ ไม่ว่าจะเป็นสิ่งที่โมเดลขนาดใหญ่สามารถทำได้หรือสิ่งที่โมเดลขนาดใหญ่ไม่สามารถทำได้ ยังอยู่ในช่วงเริ่มต้น
“เราหวังเป็นอย่างยิ่งว่าผู้ใช้จะค้นพบและรายงานกรณีขอบเพิ่มเติม (Corner กรณี) ไม่ว่าจะเป็นล่าสุด "อันไหนใหญ่กว่าระหว่าง 9.9 ถึง 9.11 อันไหนใหญ่กว่าระหว่าง 13.8 ถึง 13.11" หรือ 'สตรอเบอร์รี่' ก่อนหน้าที่มี 'r' หลายตัว การค้นพบกรณีขอบเขตเหล่านี้ช่วยให้เราเพิ่มขอบเขตได้ ของความสามารถแบบโมเดลขนาดใหญ่ แต่เพื่อแก้ปัญหาได้อย่างสมบูรณ์ เราไม่สามารถพึ่งพาการซ่อมแซมแต่ละกรณีได้ เนื่องจากสถานการณ์เหล่านี้ยากจะหมดไปเช่นเดียวกับสถานการณ์ที่ต้องเผชิญกับการขับขี่แบบอัตโนมัติ สิ่งที่เราต้องทำเพิ่มเติมคือการปรับปรุงระดับความฉลาดของโมเดลพื้นฐานที่ซ่อนอยู่อย่างต่อเนื่องเพื่อสร้างโมเดลขนาดใหญ่ มีประสิทธิภาพและครอบคลุมมากขึ้น โดยยังคงทำงานได้ดีในสถานการณ์ที่ซับซ้อนและสุดขั้วต่างๆ”
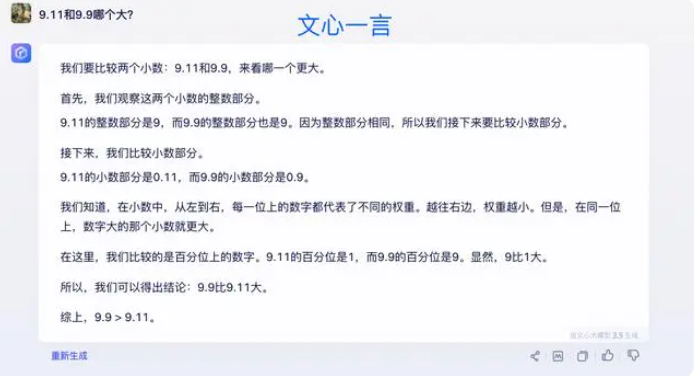
ผู้เชี่ยวชาญบางคนเชื่อว่ากุญแจสำคัญในการปรับปรุงความสามารถทางคณิตศาสตร์ของแบบจำลองขนาดใหญ่อยู่ที่คลังข้อมูลการฝึกอบรม โมเดลภาษาขนาดใหญ่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลต้นฉบับจากอินเทอร์เน็ตเป็นหลัก ซึ่งมีปัญหาทางคณิตศาสตร์และวิธีแก้ปัญหาค่อนข้างน้อย ดังนั้นการฝึกอบรมโมเดลขนาดใหญ่ในอนาคตจึงต้องมีการสร้างอย่างเป็นระบบมากขึ้น โดยเฉพาะในแง่ของการใช้เหตุผลที่ซับซ้อน
ผลการทดสอบสะท้อนถึงข้อบกพร่องของโมเดล AI ขนาดใหญ่ในปัจจุบันในด้านความสามารถในการให้เหตุผลทางคณิตศาสตร์ และยังให้แนวทางสำหรับการปรับปรุงโมเดลในอนาคตอีกด้วย การปรับปรุงความสามารถทางคณิตศาสตร์ของ AI ต้องใช้ข้อมูลและอัลกอริธึมการฝึกอบรมที่สมบูรณ์ยิ่งขึ้น ซึ่งจะเป็นกระบวนการสำรวจและปรับปรุงอย่างต่อเนื่อง