สาขาวิชาปัญญาประดิษฐ์มีการเปลี่ยนแปลงในแต่ละวัน และการให้เหตุผลเชิงสาเหตุได้กลายเป็นหัวข้อวิจัยที่ได้รับความนิยมในช่วงไม่กี่ปีที่ผ่านมา โมเดลแมชชีนเลิร์นนิงแบบดั้งเดิมมักจะขาดการให้เหตุผลเชิงตรรกะ และพบว่าเป็นการยากที่จะเข้าใจความสัมพันธ์เชิงสาเหตุเบื้องหลังเหตุการณ์ต่างๆ วันนี้ บรรณาธิการของ Downcodes จะแนะนำรายงานการวิจัยจากสถาบันต่างๆ เช่น Microsoft และ MIT ซึ่งเสนอกลยุทธ์การฝึกอบรมการเรียนรู้ของเครื่องที่ล้ำหน้า ซึ่งปรับปรุงความสามารถในการให้เหตุผลเชิงตรรกะของโมเดลขนาดใหญ่ได้อย่างมาก และแม้แต่โมเดล Transformer ขนาดเล็ก ก็เทียบได้กับ GPT- 4 ความสามารถในการให้เหตุผล เรามาดูผลการวิจัยที่น่าประทับใจนี้กันดีกว่า
ในยุคที่ข้อมูลล้นหลามเช่นนี้ เราจัดการกับอุปกรณ์อัจฉริยะทุกวัน คุณเคยสงสัยบ้างไหมว่าผู้ชายที่ดูเหมือนฉลาดเหล่านี้รู้จักที่จะนำร่มมาเพราะฝนตกได้อย่างไร เบื้องหลังสิ่งนี้คือการปฏิวัติอันลึกซึ้งในด้านการใช้เหตุผลเชิงสาเหตุ
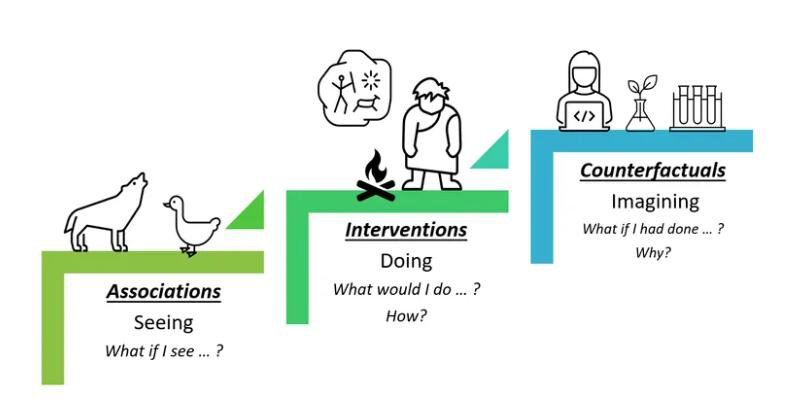
กลุ่มนักวิจัยจากสถาบันการศึกษาที่มีชื่อเสียง รวมถึง Microsoft และ MIT ได้พัฒนากลยุทธ์การฝึกอบรมการเรียนรู้ของเครื่องที่ก้าวล้ำ กลยุทธ์นี้ไม่เพียงแต่เอาชนะข้อบกพร่องของโมเดลการเรียนรู้ของเครื่องขนาดใหญ่ในการให้เหตุผลเชิงตรรกะ แต่ยังได้รับการปรับปรุงที่สำคัญผ่านขั้นตอนต่อไปนี้:
วิธีการฝึกอบรมที่ไม่เหมือนใคร: ผู้วิจัยใช้วิธีการฝึกอบรมแบบใหม่ที่อาจแตกต่างจากเทคนิคการฝึกอบรมการเรียนรู้ของเครื่องแบบเดิมๆ
การปรับปรุงการใช้เหตุผลเชิงตรรกะ: วิธีการของพวกเขาปรับปรุงความสามารถในการให้เหตุผลเชิงตรรกะของแบบจำลองขนาดใหญ่ได้อย่างมาก โดยช่วยแก้ปัญหาความท้าทายที่มีอยู่ก่อนหน้านี้
ใช้สาเหตุเพื่อสร้างชุดการฝึกอบรม: ทีมวิจัยใช้แบบจำลองเชิงสาเหตุเพื่อสร้างชุดข้อมูลการฝึกอบรม โมเดลนี้สามารถเปิดเผยการเชื่อมโยงเชิงสาเหตุระหว่างตัวแปรและช่วยฝึกแบบจำลองที่สามารถเข้าใจตรรกะเชิงสาเหตุเบื้องหลังข้อมูลได้
สอนสัจพจน์พื้นฐานของแบบจำลอง: สอนหลักเหตุผลพื้นฐานในด้านตรรกะและคณิตศาสตร์ให้กับแบบจำลองโดยตรง เพื่อช่วยให้แบบจำลองใช้เหตุผลเชิงตรรกะได้ดีขึ้น
ประสิทธิภาพอันน่าทึ่งของ Transformer รุ่นเล็ก: แม้ว่าพารามิเตอร์ของโมเดลจะมีเพียง 67 ล้าน แต่โมเดล Transformer ที่ได้รับการฝึกด้วยวิธีนี้ก็เทียบได้กับ GPT-4 ในแง่ของความสามารถในการให้เหตุผล
การใช้เหตุผลเชิงสาเหตุอาจดูเหมือนเป็นการอนุรักษ์ของนักปรัชญา แต่ในความเป็นจริงแล้ว มันได้แทรกซึมเข้าไปในทุกแง่มุมของชีวิตของเราแล้ว สำหรับปัญญาประดิษฐ์ การเรียนรู้การใช้เหตุผลเชิงสาเหตุก็เหมือนกับการเรียนรู้ที่จะอธิบายโลกโดยใช้ "เพราะ...ดังนั้น..." แต่ AI ไม่ได้เกิดมาพร้อมกับสิ่งนี้ พวกเขาจำเป็นต้องเรียนรู้ และกระบวนการเรียนรู้นี้คือเรื่องราวของบทความนี้
วิธีการฝึกอบรมสัจพจน์:
ลองนึกภาพคุณมีนักเรียนที่ฉลาดมากแต่ไม่มีเงื่อนงำเกี่ยวกับเหตุและผลในโลกนี้ คุณจะสอนมันอย่างไร นักวิจัยคิดวิธีแก้ปัญหา - การฝึกสัจพจน์ นี่เหมือนกับการให้ "คู่มือเชิงสาเหตุ" แก่ AI และปล่อยให้ AI เรียนรู้วิธีระบุและใช้กฎเชิงสาเหตุผ่านคู่มือนี้
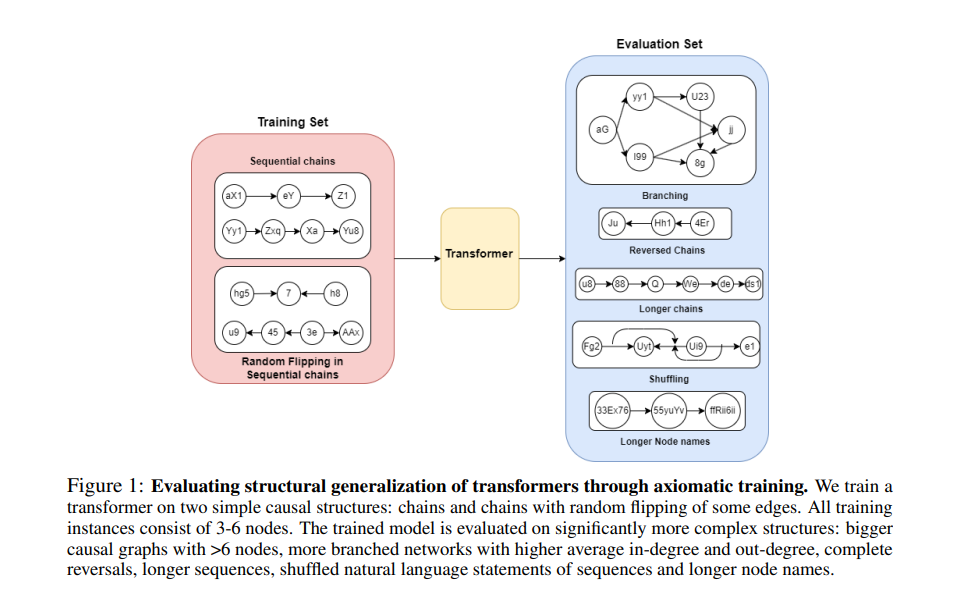
นักวิจัยได้ทำการทดลองกับโมเดลหม้อแปลงไฟฟ้าและพบว่าวิธีการฝึกนี้ใช้งานได้จริง AI ไม่เพียงแต่เรียนรู้ที่จะระบุความสัมพันธ์เชิงสาเหตุบนกราฟขนาดเล็กเท่านั้น แต่ยังสามารถนำความรู้นี้ไปใช้กับกราฟขนาดใหญ่ได้อีกด้วย มันไม่เคยเห็นภาพใหญ่เช่นนี้มาก่อน
งานวิจัยชิ้นนี้มีส่วนสนับสนุนในการมอบวิธีการใหม่สำหรับ AI ในการเรียนรู้การอนุมานเชิงสาเหตุจากข้อมูลเชิงรับ เปรียบเสมือนการให้ "วิธีคิด" แบบใหม่แก่ AI เพื่อให้สามารถเข้าใจและอธิบายโลกได้ดียิ่งขึ้น
การวิจัยนี้ไม่เพียงแต่ช่วยให้เราเห็นความเป็นไปได้ของการเรียนรู้การใช้เหตุผลเชิงสาเหตุของ AI เท่านั้น แต่ยังเปิดประตูให้เรามองเห็นสถานการณ์การประยุกต์ใช้ AI ที่เป็นไปได้ในอนาคตอีกด้วย บางทีในอนาคตอันใกล้นี้ ผู้ช่วยอัจฉริยะของเราไม่เพียงแต่ตอบคำถามเท่านั้น แต่ยังบอกเราด้วยว่าเหตุใดจึงเกิดเหตุการณ์บางอย่างขึ้น
ที่อยู่กระดาษ: https://arxiv.org/pdf/2407.07612v1
โดยรวมแล้ว งานวิจัยนี้ได้นำมาซึ่งการปรับปรุงที่สำคัญในความสามารถในการให้เหตุผลเชิงสาเหตุของปัญญาประดิษฐ์ และให้ทิศทางและความเป็นไปได้ใหม่ๆ สำหรับการพัฒนา AI ในอนาคต บรรณาธิการของ Downcodes ตั้งตารอที่จะนำเทคโนโลยีนี้ไปประยุกต์ใช้ในสาขาต่างๆ มากขึ้น ซึ่งจะทำให้ AI เข้าใจและให้บริการมนุษย์ได้ดีขึ้น