การฝึกอบรมปัญญาประดิษฐ์นั้นใช้เวลานานและสิ้นเปลืองพลังการประมวลผล ซึ่งเป็นปัญหาคอขวดในสาขา AI มาโดยตลอด เมื่อเร็วๆ นี้ ทีม DeepMind ได้เปิดตัวการศึกษาวิจัยที่ก้าวหน้าและเสนอวิธีการคัดกรองข้อมูลใหม่ที่เรียกว่า JEST ซึ่งสามารถแก้ปัญหานี้ได้อย่างมีประสิทธิภาพ เครื่องมือแก้ไข Downcodes จะให้ความเข้าใจเชิงลึกแก่คุณว่า JEST สามารถปรับปรุงประสิทธิภาพของการฝึกอบรม AI ได้อย่างมากได้อย่างไร และอธิบายหลักการทางเทคนิคที่อยู่เบื้องหลัง
ในด้านปัญญาประดิษฐ์ พลังการประมวลผลและเวลาเป็นปัจจัยสำคัญที่จำกัดความก้าวหน้าทางเทคโนโลยีมาโดยตลอด อย่างไรก็ตามผลการวิจัยล่าสุดของทีม DeepMind ได้ช่วยแก้ไขปัญหานี้ได้
พวกเขาเสนอวิธีการคัดกรองข้อมูลใหม่ที่เรียกว่า JEST ซึ่งสามารถลดเวลาการฝึกอบรม AI และความต้องการพลังงานการประมวลผลลงได้อย่างมาก โดยการคัดกรองชุดข้อมูลที่ดีที่สุดสำหรับการฝึกอบรมอย่างชาญฉลาด กล่าวกันว่าสามารถลดเวลาการฝึกอบรม AI ได้ 13 เท่า และลดความต้องการพลังการประมวลผลลง 90%
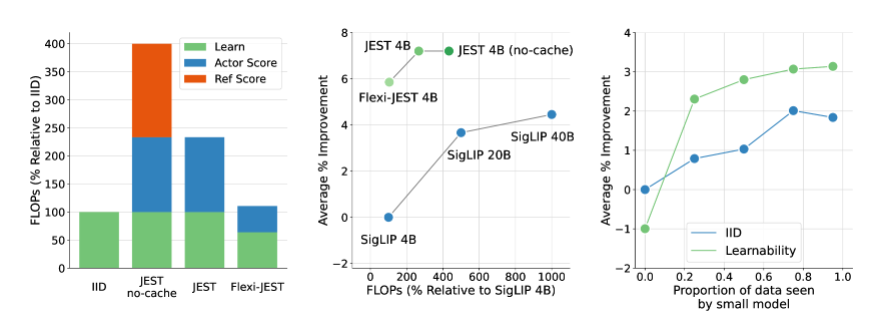
แกนหลักของวิธีการ JEST อยู่ที่การร่วมกันเลือกชุดข้อมูลที่ดีที่สุดมากกว่าตัวอย่างแต่ละตัวอย่าง ซึ่งเป็นกลยุทธ์ที่ได้รับการพิสูจน์แล้วว่ามีประสิทธิภาพโดยเฉพาะอย่างยิ่งในการเร่งการเรียนรู้แบบหลายรูปแบบ เมื่อเปรียบเทียบกับวิธีการคัดกรองข้อมูลก่อนการฝึกอบรมขนาดใหญ่แบบดั้งเดิม JEST ไม่เพียงแต่ลดจำนวนการวนซ้ำและการดำเนินการจุดลอยตัวลงอย่างมาก แต่ยังเหนือกว่าเทคโนโลยีล้ำสมัยก่อนหน้านี้ในขณะที่ใช้งบประมาณ FLOP เพียง 10% เท่านั้น
การวิจัยของทีม DeepMind เผยให้เห็นประเด็นสำคัญ 3 ประการ ได้แก่ การเลือกชุดข้อมูลที่ดีมีประสิทธิภาพมากกว่าการเลือกจุดข้อมูลทีละจุด การประมาณแบบจำลองออนไลน์สามารถใช้เพื่อกรองข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น และชุดข้อมูลขนาดเล็กคุณภาพสูงสามารถบูตเพื่อใช้ประโยชน์จากชุดข้อมูลที่มีขนาดใหญ่กว่าได้ . ชุดข้อมูลที่ไม่มีการดูแล การค้นพบนี้เป็นพื้นฐานทางทฤษฎีสำหรับประสิทธิภาพการทำงานของวิธี JEST
หลักการทำงานของ JEST คือการประเมินความสามารถในการเรียนรู้ของจุดข้อมูลโดยอาศัยการวิจัยก่อนหน้าเกี่ยวกับการสูญเสีย RHO และการรวมการสูญเสียของรูปแบบการเรียนรู้และแบบจำลองอ้างอิงที่ได้รับการฝึกอบรมล่วงหน้า โดยจะเลือกจุดข้อมูลที่ง่ายกว่าสำหรับโมเดลที่ได้รับการฝึกอบรมล่วงหน้า แต่ยากกว่าสำหรับโมเดลการเรียนรู้ในปัจจุบัน เพื่อปรับปรุงประสิทธิภาพและประสิทธิผลของการฝึกอบรม
นอกจากนี้ JEST ยังใช้วิธีการวนซ้ำโดยยึดตามการบล็อกการสุ่มตัวอย่าง Gibbs เพื่อค่อยๆ สร้างชุด และเลือกชุดย่อยตัวอย่างใหม่ตามคะแนนความสามารถในการเรียนรู้แบบมีเงื่อนไขในการวนซ้ำแต่ละครั้ง วิธีการนี้ได้รับการปรับปรุงอย่างต่อเนื่องเมื่อมีการกรองข้อมูลมากขึ้น รวมถึงการใช้เฉพาะแบบจำลองอ้างอิงที่ได้รับการฝึกอบรมล่วงหน้าเท่านั้นในการให้คะแนนข้อมูล
การวิจัยโดย DeepMind นี้ไม่เพียงแต่นำความก้าวหน้าครั้งสำคัญมาสู่ด้านการฝึกอบรม AI เท่านั้น แต่ยังนำเสนอแนวคิดและวิธีการใหม่ๆ สำหรับการพัฒนาเทคโนโลยี AI ในอนาคต ด้วยการเพิ่มประสิทธิภาพและการประยุกต์ใช้วิธี JEST เพิ่มเติม เรามีเหตุผลที่เชื่อได้ว่าการพัฒนาปัญญาประดิษฐ์จะนำไปสู่โอกาสที่กว้างขึ้น
บทความ: https://arxiv.org/abs/2406.17711
ไฮไลท์:
**การปฏิวัติประสิทธิภาพการฝึกอบรม**: วิธี JEST ของ DeepMind ช่วยลดเวลาการฝึกอบรม AI ลง 13 เท่า และลดความต้องการพลังการประมวลผลลง 90%
**การคัดกรองชุดข้อมูล**: JEST ปรับปรุงประสิทธิภาพของการเรียนรู้หลายรูปแบบอย่างมีนัยสำคัญโดยร่วมกันเลือกชุดข้อมูลที่ดีที่สุดแทนแต่ละตัวอย่าง
️ **วิธีการฝึกอบรมที่เป็นนวัตกรรม**: JEST ใช้การประมาณโมเดลออนไลน์และคำแนะนำชุดข้อมูลคุณภาพสูงเพื่อเพิ่มประสิทธิภาพการกระจายข้อมูลและความสามารถในการสรุปโมเดลของการฝึกอบรมล่วงหน้าขนาดใหญ่
การเกิดขึ้นของวิธี JEST ได้นำมาซึ่งความหวังใหม่ให้กับการฝึกอบรม AI และคาดว่ากลยุทธ์การคัดกรองข้อมูลที่มีประสิทธิภาพจะส่งเสริมการประยุกต์ใช้และการพัฒนาเทคโนโลยี AI ในสาขาต่างๆ ในอนาคต เราหวังว่าจะได้เห็นประสิทธิภาพของ JEST ในการใช้งานจริงมากขึ้น และส่งเสริมความก้าวหน้าในด้านปัญญาประดิษฐ์ต่อไป บรรณาธิการของ Downcodes จะยังคงให้ความสำคัญกับการพัฒนาที่เกี่ยวข้องและนำเสนอรายงานที่น่าตื่นเต้นแก่ผู้อ่านมากขึ้น