ในช่วงไม่กี่ปีที่ผ่านมา การพัฒนาอย่างรวดเร็วของเทคโนโลยีปัญญาประดิษฐ์ต้องอาศัยการฝึกอบรมข้อมูลขนาดใหญ่เป็นอย่างมาก อย่างไรก็ตาม บรรณาธิการของ Downcodes พบว่างานวิจัยล่าสุดจาก MIT และสถาบันอื่นๆ ชี้ให้เห็นว่าความยากในการรับข้อมูลเพิ่มขึ้นอย่างมาก ข้อมูลเครือข่ายที่ครั้งหนึ่งเคยหาได้ง่ายปัจจุบันอยู่ภายใต้ข้อจำกัดที่เข้มงวดมากขึ้น ซึ่งก่อให้เกิดความท้าทายอย่างมากต่อการฝึกอบรมและการพัฒนา AI การศึกษาซึ่งวิเคราะห์ชุดข้อมูลโอเพ่นซอร์สหลายชุดเผยให้เห็นความเป็นจริงโดยสิ้นเชิงนี้
เบื้องหลังการพัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ ปัญหาร้ายแรงกำลังปรากฏ—ความยากในการรับข้อมูลกำลังเพิ่มขึ้น การวิจัยล่าสุดจาก MIT และสถาบันอื่นๆ พบว่าข้อมูลเว็บที่ครั้งหนึ่งเคยเข้าถึงได้ง่าย ปัจจุบันกลายเป็นเรื่องยากในการเข้าถึงมากขึ้นเรื่อยๆ ซึ่งเป็นความท้าทายสำคัญต่อการฝึกอบรมและการวิจัย AI
นักวิจัยพบว่าเว็บไซต์ที่รวบรวมข้อมูลโดยชุดข้อมูลโอเพ่นซอร์สหลายชุด เช่น C4, RefineWeb, Dolma ฯลฯ กำลังกระชับข้อตกลงใบอนุญาตอย่างรวดเร็ว สิ่งนี้ไม่เพียงส่งผลต่อการฝึกอบรมโมเดล AI เชิงพาณิชย์เท่านั้น แต่ยังเป็นอุปสรรคต่อการวิจัยโดยองค์กรวิชาการและองค์กรไม่แสวงหาผลกำไรอีกด้วย

การวิจัยนี้ดำเนินการโดยหัวหน้าทีม 4 คนจาก MIT Media Lab, Wellesley College, Raive สตาร์ทอัพด้าน AI และสถาบันอื่นๆ พวกเขาสังเกตว่าข้อจำกัดด้านข้อมูลกำลังแพร่หลาย และความไม่สมดุลและความไม่สอดคล้องกันของใบอนุญาตก็เริ่มชัดเจนมากขึ้น
ทีมวิจัยใช้ Robots Exclusion Protocol (REP) และข้อกำหนดในการให้บริการ (ToS) ของเว็บไซต์เป็นวิธีการวิจัย พวกเขาพบว่าแม้แต่โปรแกรมรวบรวมข้อมูลจากบริษัท AI ขนาดใหญ่อย่าง OpenAI ก็ต้องเผชิญกับข้อจำกัดที่เข้มงวดมากขึ้น
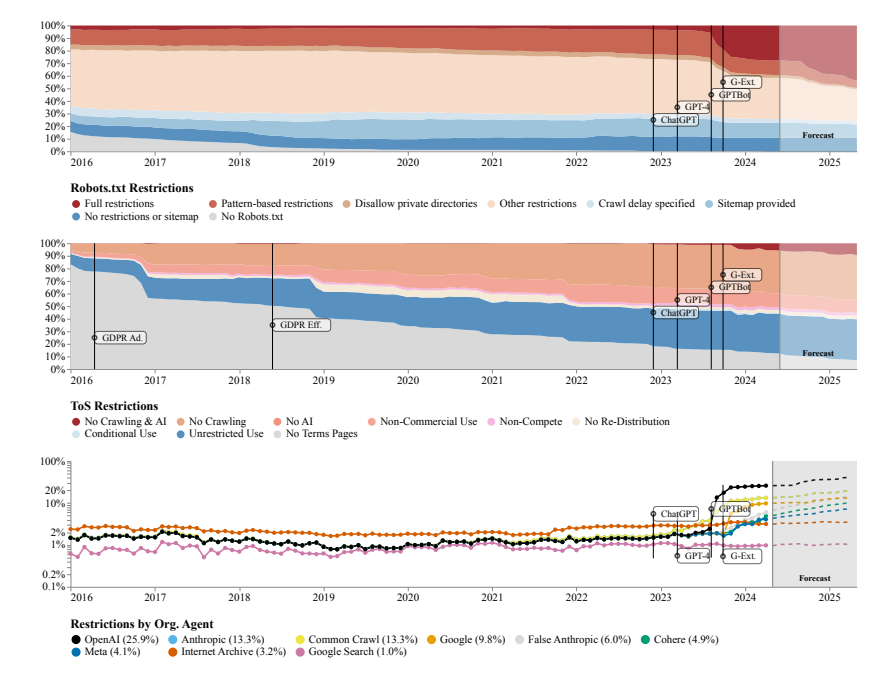
โมเดล SARIMA คาดการณ์ว่าในอนาคต ไม่ว่าจะผ่าน robots.txt หรือ ToS ข้อจำกัดด้านข้อมูลเว็บไซต์จะยังคงเพิ่มขึ้นต่อไป สิ่งนี้ชี้ให้เห็นว่าการเข้าถึงข้อมูลเครือข่ายแบบเปิดจะยากขึ้น
การศึกษายังพบว่าข้อมูลที่รวบรวมข้อมูลจากอินเทอร์เน็ตไม่สอดคล้องกับวัตถุประสงค์การฝึกอบรมของโมเดล AI ซึ่งอาจส่งผลกระทบต่อการจัดตำแหน่งโมเดล การรวบรวมข้อมูล และลิขสิทธิ์
ทีมวิจัยเรียกร้องให้มีข้อตกลงที่ยืดหยุ่นมากขึ้นซึ่งสะท้อนถึงความต้องการของเจ้าของเว็บไซต์ แยกกรณีการใช้งานที่ได้รับอนุญาตและไม่อนุญาต และประสานกับข้อกำหนดในการให้บริการ ในเวลาเดียวกัน พวกเขาต้องการให้นักพัฒนา AI สามารถใช้ข้อมูลบนเว็บแบบเปิดสำหรับการฝึกอบรม และหวังว่ากฎหมายในอนาคตจะสนับสนุนเรื่องนี้
ที่อยู่กระดาษ: https://www.dataprovenance.org/Consent_in_Crisis.pdf
การวิจัยครั้งนี้ส่งสัญญาณเตือนถึงปัญหาการได้มาซึ่งข้อมูลในด้านปัญญาประดิษฐ์ และยังก่อให้เกิดความท้าทายใหม่สำหรับการฝึกอบรมและพัฒนาโมเดล AI ในอนาคต วิธีสร้างสมดุลการได้มาของข้อมูลกับสิทธิและผลประโยชน์ของเจ้าของเว็บไซต์จะกลายเป็นประเด็นสำคัญที่ต้องพิจารณาและแก้ไขอย่างจริงจังในด้านปัญญาประดิษฐ์ บรรณาธิการของ Downcodes แนะนำให้ใส่ใจกับบทความนี้เพื่อเรียนรู้รายละเอียดเพิ่มเติม