Mini-Omni ซึ่งเป็นโมเดลภาษาขนาดใหญ่หลายรูปแบบแบบโอเพ่นซอร์ส กำลังปฏิวัติเทคโนโลยีการโต้ตอบด้วยเสียง โดยผสานรวมเทคโนโลยีขั้นสูงเพื่อให้รับรู้อินพุตและเอาต์พุตเสียงแบบเรียลไทม์ และมีความสามารถในการคิดและพูดในเวลาเดียวกัน มอบประสบการณ์ปฏิสัมพันธ์ระหว่างมนุษย์กับคอมพิวเตอร์ที่เป็นธรรมชาติและราบรื่นยิ่งขึ้น ข้อได้เปรียบหลักของ Mini-Omni อยู่ที่ความสามารถในการประมวลผลคำพูดแบบเรียลไทม์ตั้งแต่ต้นทางถึงปลายทาง ไม่จำเป็นต้องกำหนดค่ารุ่น ASR หรือ TTS เพิ่มเติมเพื่อให้การสนทนาราบรื่น รองรับอินพุตโมดอลหลายอินพุตและแปลงได้อย่างยืดหยุ่นเพื่อปรับให้เข้ากับสถานการณ์ที่ซับซ้อนต่างๆ และตอบสนองความต้องการที่หลากหลาย
ปัจจุบัน ด้วยการพัฒนาอย่างรวดเร็วของปัญญาประดิษฐ์ โมเดลภาษาโอเพ่นซอร์สขนาดใหญ่หลายรูปแบบที่เรียกว่า Mini-Omni กำลังเป็นผู้นำด้านนวัตกรรมของเทคโนโลยีการโต้ตอบด้วยเสียง ระบบ AI นี้บูรณาการเข้ากับเทคโนโลยีขั้นสูงหลายอย่าง ไม่เพียงแต่เปิดใช้งานอินพุตและเอาต์พุตเสียงแบบเรียลไทม์เท่านั้น แต่ยังมีความสามารถพิเศษในการคิดและพูดในเวลาเดียวกัน ทำให้ผู้ใช้ได้รับประสบการณ์การโต้ตอบที่เป็นธรรมชาติอย่างที่ไม่เคยมีมาก่อน
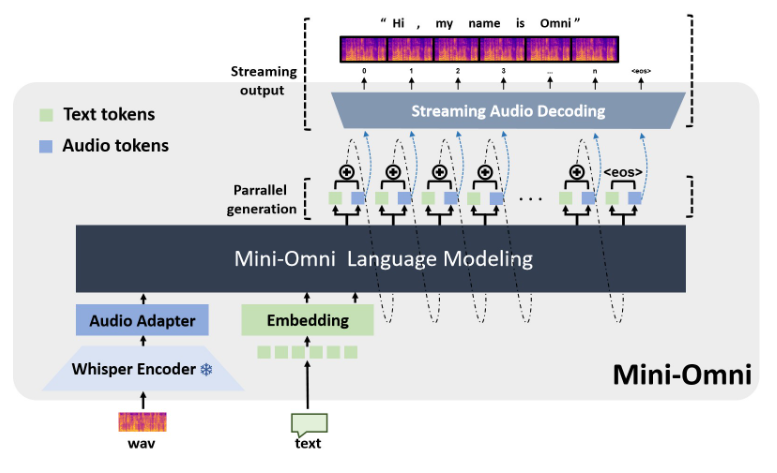
ข้อได้เปรียบหลักของ Mini-Omni อยู่ที่ความสามารถในการประมวลผลเสียงแบบเรียลไทม์แบบ end-to-end ผู้ใช้สามารถเพลิดเพลินกับการสนทนาด้วยเสียงที่ราบรื่นโดยไม่ต้องกำหนดค่าเพิ่มเติมของโมเดลการรู้จำเสียงพูดอัตโนมัติ (ASR) หรือข้อความเป็นคำพูด (TTS) การออกแบบที่ไร้รอยต่อนี้ช่วยปรับปรุงประสบการณ์ผู้ใช้อย่างมาก และทำให้การโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์เป็นธรรมชาติและใช้งานง่ายยิ่งขึ้น
นอกจากฟังก์ชั่นเสียงแล้ว Mini-Omni ยังรองรับการป้อนข้อมูลในโหมดต่างๆ เช่น ข้อความ และสามารถสลับระหว่างโหมดต่างๆ ได้อย่างยืดหยุ่น ความสามารถในการประมวลผลหลายรูปแบบนี้ช่วยให้โมเดลสามารถปรับให้เข้ากับสถานการณ์การโต้ตอบที่ซับซ้อนต่างๆ และตอบสนองความต้องการที่หลากหลายของผู้ใช้
สิ่งที่ควรกล่าวถึงเป็นพิเศษคือฟังก์ชัน Any Model Can Talk ของ Mini-Omni นวัตกรรมนี้ช่วยให้โมเดล AI อื่นๆ สามารถรวมความสามารถด้านเสียงแบบเรียลไทม์ของ Mini-Omni ได้อย่างง่ายดาย ซึ่งขยายความเป็นไปได้อย่างมากสำหรับแอปพลิเคชัน AI สิ่งนี้ไม่เพียงแต่ช่วยให้นักพัฒนามีทางเลือกมากขึ้นเท่านั้น แต่ยังปูทางไปสู่การประยุกต์ใช้เทคโนโลยี AI แบบข้ามสาขาอีกด้วย
ในแง่ของประสิทธิภาพ Mini-Omni แสดงให้เห็นถึงความแข็งแกร่งที่ครอบคลุม ไม่เพียงแต่ทำงานได้ดีในงานคำพูดแบบดั้งเดิม เช่น การรู้จำเสียง (ASR) และการสร้างเสียงพูด (TTS) แต่ยังแสดงให้เห็นถึงศักยภาพที่แข็งแกร่งในงานหลายรูปแบบที่ต้องใช้ความสามารถในการให้เหตุผลที่ซับซ้อน เช่น TextQA และ SpeechQA ความสามารถที่ครอบคลุมนี้ช่วยให้ Mini-Omni สามารถจัดการกับสถานการณ์การโต้ตอบที่ซับซ้อนที่หลากหลาย ตั้งแต่คำสั่งเสียงธรรมดาไปจนถึงคำถามและคำตอบงานที่ต้องใช้การคิดเชิงลึก
การใช้งานทางเทคนิคของ Mini-Omni รวมเอาโมเดลและเทคโนโลยี AI ขั้นสูงหลายตัวเข้าด้วยกัน โดยจะใช้ Qwen2 เป็นพื้นฐานของโมเดลภาษาขนาดใหญ่ ใช้ litGPT สำหรับการฝึกอบรมและการอนุมาน ใช้เสียงกระซิบสำหรับการเข้ารหัสเสียง และ snac รับผิดชอบในการถอดรหัสเสียง วิธีการผสมหลายเทคโนโลยีนี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพโดยรวมของแบบจำลองเท่านั้น แต่ยังเพิ่มความสามารถในการปรับตัวในสถานการณ์ต่างๆ อีกด้วย
สำหรับนักพัฒนาและนักวิจัย Mini-Omni มอบความสะดวกในการใช้งาน ด้วยขั้นตอนการติดตั้งง่ายๆ ผู้ใช้สามารถเปิด Mini-Omni ในสภาพแวดล้อมท้องถิ่นของตน และดำเนินการสาธิตเชิงโต้ตอบผ่านเครื่องมือ เช่น Streamlit และ Gradio ฟีเจอร์ที่เปิดกว้างและใช้งานง่ายนี้ให้การสนับสนุนอย่างมากสำหรับการประยุกต์ใช้เทคโนโลยี AI ที่เป็นนวัตกรรมและเป็นที่นิยม
ที่อยู่โครงการ: https://github.com/gpt-omni/mini-omni
ด้วยฟังก์ชันอันทรงพลัง การใช้งานที่สะดวกสบาย และฟีเจอร์โอเพ่นซอร์ส Mini-Omni นำความเป็นไปได้ใหม่มาสู่ด้านการโต้ตอบด้วยเสียงของ AI และสมควรได้รับความสนใจและการสำรวจจากนักพัฒนาและนักวิจัย การพัฒนาในอนาคตก็คุ้มค่ากับการรอคอยเช่นกัน