เมื่อเร็วๆ นี้ โมเดล AI แบบโอเพ่นซอร์ส Reflection70B ได้รับความสนใจอย่างกว้างขวางในอุตสาหกรรม เนื่องจากข้อขัดแย้งด้านประสิทธิภาพ โมเดลดังกล่าวเผยแพร่โดย HyperWrite ซึ่งแต่เดิมอ้างว่าเป็นโมเดลโอเพ่นซอร์สที่ทรงพลังที่สุดในโลก และดึงดูดความสนใจอย่างมากเนื่องจากประสิทธิภาพที่ยอดเยี่ยมในการทดสอบโดยบุคคลที่สาม อย่างไรก็ตาม สถาบันอิสระและผู้ใช้บางแห่งตั้งคำถามถึงประสิทธิภาพของมัน และผลการทดสอบแตกต่างไปจากคำกล่าวอ้างเบื้องต้นของ HyperWrite อย่างมีนัยสำคัญ
โมเดล AI แบบโอเพ่นซอร์ส Reflection70B ซึ่งเพิ่งเปิดตัว เพิ่งถูกตั้งคำถามอย่างกว้างขวางจากอุตสาหกรรม
โมเดลนี้เปิดตัวโดย HyperWrite สตาร์ทอัพในนิวยอร์ก ซึ่งอ้างว่าเป็นเวอร์ชัน Llama3.1 ของ Meta ได้รับความสนใจเนื่องจากประสิทธิภาพที่ยอดเยี่ยมในการทดสอบโดยบุคคลที่สาม อย่างไรก็ตาม เมื่อมีการประกาศผลการทดสอบบางส่วน ชื่อเสียงของ Reflection70B ก็เริ่มถูกท้าทาย
สาเหตุของเรื่องนี้ก็คือ Matt Shumer ผู้ร่วมก่อตั้งและซีอีโอของ HyperWrite ได้ประกาศ Reflection70B บนโซเชียลมีเดีย X เมื่อวันที่ 6 กันยายน และเรียกสิ่งนี้อย่างมั่นใจว่า "โมเดลโอเพ่นซอร์สที่แข็งแกร่งที่สุดในโลก"
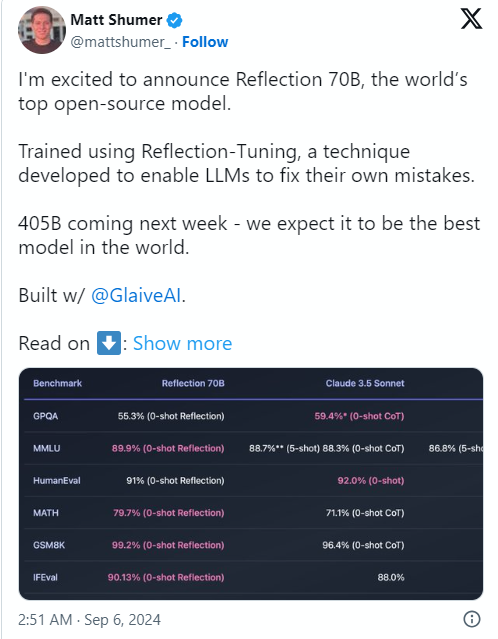
Shumer ยังได้แบ่งปันเกี่ยวกับเทคโนโลยี "การปรับแต่งแบบสะท้อนแสง" ของโมเดล โดยอ้างว่าวิธีนี้ช่วยให้โมเดลตรวจสอบตัวเองก่อนที่จะสร้างเนื้อหา ซึ่งจะช่วยปรับปรุงความแม่นยำ
อย่างไรก็ตาม วันรุ่งขึ้นหลังจากการประกาศของ HyperWrite กลุ่ม Artificial Analysis ซึ่งเป็นกลุ่มที่เชี่ยวชาญใน "การวิเคราะห์อิสระของโมเดล AI และผู้ให้บริการโฮสต์" ได้เผยแพร่การวิเคราะห์ของตนเองใน X โดยสังเกตว่าพวกเขาประเมินคะแนน MMLU (Massive Multitask Language Undering) ของ Reflection Llama3.170B (ความเข้าใจภาษามัลติทาสก์ขนาดใหญ่) เหมือนกับ Llama370B แต่ต่ำกว่า Llama3.170B ของ Meta อย่างมาก ซึ่งแตกต่างอย่างมีนัยสำคัญจากผลลัพธ์ที่เผยแพร่ครั้งแรกโดย HyperWrite/Shumer
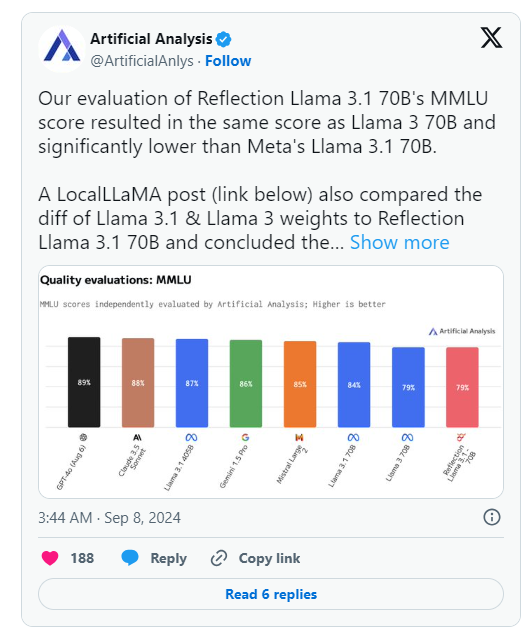
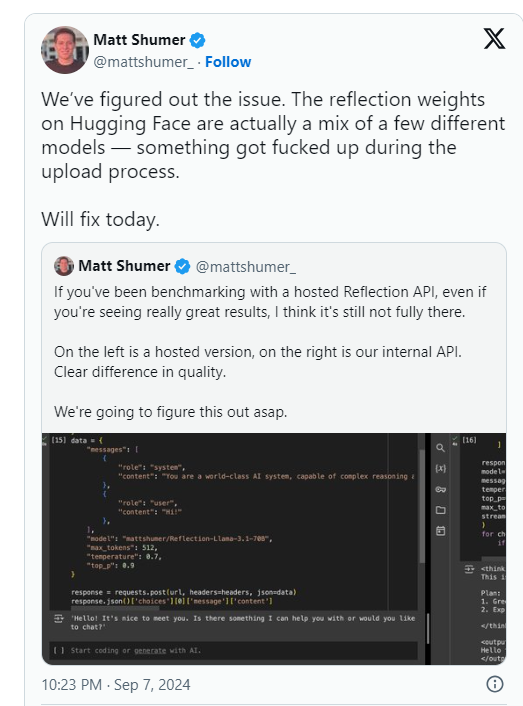
Shumer กล่าวในภายหลังว่ามีปัญหากับน้ำหนักของ Reflection70B (หรือการตั้งค่าสำหรับโมเดลโอเพ่นซอร์ส) ในระหว่างการอัปโหลดไปยัง Hugging Face (พื้นที่เก็บข้อมูลโฮสต์โค้ด AI บุคคลที่สามและบริษัท) ซึ่งอาจส่งผลให้ประสิทธิภาพแย่ลงกว่า "API ภายใน" ของ HyperWrite “เวอร์ชั่น..
การวิเคราะห์เชิงประดิษฐ์กล่าวในแถลงการณ์ภายหลังว่าพวกเขาสามารถเข้าถึง API ส่วนตัวและเห็นประสิทธิภาพที่น่าประทับใจ แต่ไม่ถึงระดับที่ระบุไว้ในตอนแรก เนื่องจากการทดสอบนี้ดำเนินการบน API ส่วนตัว พวกเขาจึงไม่สามารถตรวจสอบสิ่งที่พวกเขากำลังทดสอบได้อย่างอิสระ
กลุ่มได้หยิบยกประเด็นสำคัญสองประเด็นที่ตั้งคำถามอย่างจริงจังถึงคำกล่าวอ้างด้านประสิทธิภาพดั้งเดิมของ HyperWrite และ Shumer:
ในขณะเดียวกัน ผู้ใช้ในการเรียนรู้ของเครื่องและชุมชน AI หลายแห่งบน Reddit ยังได้ตั้งคำถามถึงประสิทธิภาพและต้นกำเนิดที่อ้างสิทธิ์ของ Reflection70B บางคนชี้ให้เห็น ว่า Reflection70B ดูเหมือนจะเป็นตัวแปรของ Llama3 มากกว่า Llama-3.1 โดยอิงจากการเปรียบเทียบแบบจำลองที่โพสต์โดยบุคคลที่สามบน Github ทำให้เกิดข้อสงสัยเพิ่มเติมเกี่ยวกับการอ้างสิทธิ์ดั้งเดิมของ Shumer และ HyperWrite
ซึ่งส่งผลให้มีผู้ใช้ X อย่างน้อยหนึ่งราย Shin Megami Boson โพสต์เมื่อวันที่ 8 กันยายน ET
เมื่อเวลา 20:07 น. EDT Shumer กล่าวหา Shumer ต่อสาธารณะว่ามี "พฤติกรรมฉ้อโกง" ในชุมชนการวิจัย AI และเผยแพร่รายการภาพหน้าจอและหลักฐานอื่น ๆ มากมาย
คนอื่น ๆ กล่าวหาว่าแบบจำลองนี้เป็น "wrapper" หรือแอปพลิเคชันที่สร้างขึ้นจาก Claude3 ของ Anthropic ซึ่งเป็นคู่แข่งที่เป็นกรรมสิทธิ์/ปิดแหล่งที่มา
อย่างไรก็ตาม ผู้ใช้ X คนอื่นๆ ได้ออกมาปกป้อง Shumer และ Reflection70B โดยที่บางคนก็แสดงประสิทธิภาพที่น่าประทับใจในตอนท้ายของโมเดลด้วย
ปัจจุบันชุมชนการวิจัย AI กำลังรอคำตอบของ Shumer ต่อข้อกล่าวหาเรื่องการฉ้อโกงและน้ำหนักโมเดลที่อัปเดตบน Hugging Face
หลังจากการเปิดตัวรุ่น Reflection70B ประสิทธิภาพก็ถูกตั้งคำถาม โดยผลการทดสอบไม่สามารถจำลองการอ้างสิทธิ์เบื้องต้นได้
⚙️ ผู้ก่อตั้ง HyperWrite อธิบายว่าปัญหาการอัปโหลดโมเดลทำให้ประสิทธิภาพลดลง และเรียกร้องให้ให้ความสนใจกับเวอร์ชันที่อัปเดต
โมเดลดังกล่าวได้รับการถกเถียงกันอย่างถึงพริกถึงขิงบนโซเชียลมีเดีย โดยมีข้อกล่าวหาและคำแก้ต่างปะปนกัน
ปัจจุบัน เหตุการณ์ Reflection70B ยังคงหมักหมมต่อไป และผลลัพธ์สุดท้ายยังต้องรอการสอบสวนและการตอบสนองเพิ่มเติม เหตุการณ์นี้ยังเตือนเราว่าเราควรระมัดระวังในการส่งเสริมประสิทธิภาพของโมเดล AI ใดๆ และอาศัยผลการตรวจสอบที่เป็นอิสระในการตัดสิน