ทีมฐานข้อมูลแบบจำลองขนาดใหญ่ OpenDataLab ห้องปฏิบัติการปัญญาประดิษฐ์เซี่ยงไฮ้ (Shanghai AI Laboratory) เปิดตัวเครื่องมือดึงข้อมูลอัจฉริยะตัวใหม่ MinerU ที่ฟอรัมหลัก WAIC Science Frontier ประจำปี 2024 เครื่องมือโอเพ่นซอร์สนี้มีจุดมุ่งหมายเพื่อลดความซับซ้อนของกระบวนการประมวลผลข้อมูล AI และช่วยให้นักวิจัยดึงข้อมูลคุณภาพสูงจากเอกสารขนาดใหญ่ได้อย่างมีประสิทธิภาพมากขึ้น MinerU รองรับรูปแบบเอกสารที่หลากหลาย รวมถึง PDF, หน้าเว็บ, epub, mobi และ docx ฯลฯ และแปลงเป็นรูปแบบ Markdown ที่ง่ายต่อการวิเคราะห์ โมดูลการทำงานหลัก Magic-PDF และ Magic-Doc มุ่งเน้นไปที่การแยกเอกสาร PDF และหน้าเว็บ/e-books ตามลำดับ และใช้โมเดลต่างๆ เช่น LayoutLMv3, YOLOv8, UniMERNet และ PaddleOCR เพื่อให้ดึงข้อมูลคุณภาพสูง ซึ่งช่วยปรับปรุงข้อมูลได้อย่างมาก ประสิทธิภาพการประมวลผล
ที่ฟอรัมหลัก WAIC Science Frontier ปี 2024 ทีมฐานข้อมูลแบบจำลองขนาดใหญ่ OpenDataLab ของ Shanghai Artificial Intelligence Laboratory (Shanghai AI Laboratory) ได้เปิดตัวเครื่องมือดึงข้อมูลอัจฉริยะตัวใหม่ที่เรียกว่า MinerU เครื่องมือนี้ได้รับการออกแบบมาเพื่อลดความซับซ้อนของกระบวนการประมวลผลข้อมูล AI และช่วยให้นักวิจัย AI ดึงข้อมูลคุณภาพสูงจากเอกสารขนาดใหญ่
MinerU เป็นเอกสารโอเพ่นซอร์สแบบครบวงจรและเครื่องมือแยกข้อมูลหน้าเว็บที่สามารถแปลงเอกสาร PDF หลายรูปแบบ รวมถึงรูปภาพ ตาราง สูตร ฯลฯ ให้เป็นรูปแบบ Markdown ที่ชัดเจนและง่ายต่อการวิเคราะห์ นอกจากนี้ยังสามารถแยกวิเคราะห์และแยกเนื้อหาอย่างเป็นทางการจากหน้าเว็บที่มีข้อมูลการแทรกแซง เช่น โฆษณา ได้อย่างรวดเร็ว และรองรับการแปลงเป็นชุดของรูปแบบต่างๆ เช่น epub, mobi, docx ฯลฯ ลงใน Markdown
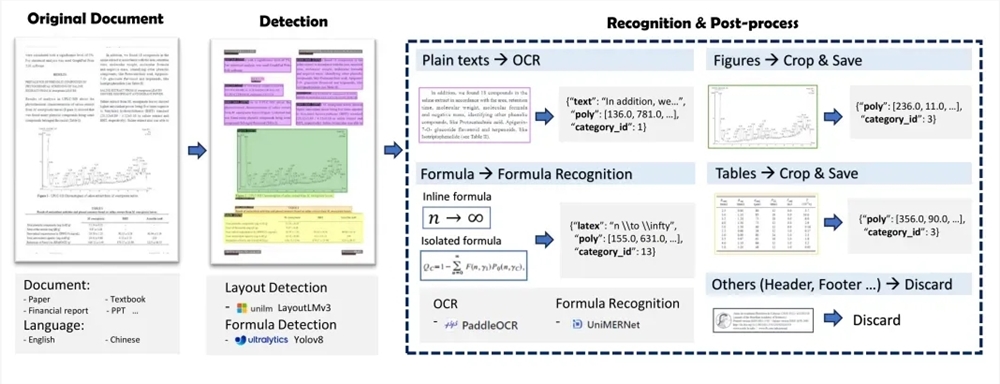
MinerU ประกอบด้วยสองส่วนหลัก: Magic-PDF และ Magic-Doc Magic-PDF มุ่งเน้นไปที่การแยกเอกสาร PDF และแปลง PDF เป็นรูปแบบ Markdown โดยสามารถระบุองค์ประกอบเค้าโครง PDF ได้อย่างรวดเร็ว ลบเนื้อหาที่ไม่ใช่ข้อความโดยอัตโนมัติ และคงโครงสร้างและรูปแบบของเอกสารต้นฉบับไว้ Magic-Doc มีหน้าที่ในการแยกหน้าเว็บและ e-book ซึ่งสนับสนุนการดึงข้อมูลหน้าเว็บทั่วไป เช่น บทความ ฟอรั่ม เพลง วิดีโอ ฯลฯ รวมถึงการแปลงรูปแบบ e-book
ในระดับเทคนิค กระบวนการแยกเอกสาร PDF ของ MinerU ประกอบด้วยการประมวลผลล่วงหน้าการจำแนกประเภทเอกสาร PDF การวิเคราะห์แบบจำลอง การประมวลผลไปป์ไลน์ และการตรวจสอบคุณภาพของผลลัพธ์การแยก PDF โดยจะใช้โมเดลต่างๆ มากมาย เช่น LayoutLMv3, YOLOv8, UniMERNet และ PaddleOCR เพื่อให้การแยกข้อมูลเอกสารมีคุณภาพสูง
การเปิดตัว MinerU ไม่เพียงแต่ช่วยให้นักวิจัย AI มีเครื่องมือประมวลผลข้อมูลอันทรงพลังเท่านั้น แต่ยังช่วยส่งเสริมการอัปเกรดระบบเครื่องมือลูกโซ่ทั้งหมดสำหรับการพัฒนาโมเดลขนาดใหญ่และการใช้งานอีกด้วย
ลิงก์ประสบการณ์ชุมชนเวทมนตร์:
https://modelscope.cn/studios/OpenDataLab/MinerU
ลิงค์รหัสโอเพ่นซอร์ส:
https://github.com/opendatalab/MinerU/
โมเดลโอเพ่นซอร์ส MinerU (PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
โอเพ่นซอร์สและความสะดวกในการใช้งานของ MinerU จะช่วยอำนวยความสะดวกให้กับนักวิจัยและนักพัฒนา AI อย่างมาก เร่งประสิทธิภาพการประมวลผลข้อมูลในสาขา AI และให้การสนับสนุนอย่างมากสำหรับการพัฒนาโมเดลขนาดใหญ่ ยินดีต้อนรับสู่ลิงค์เพื่อสัมผัสประสบการณ์และใช้ MinerU