การปรับแต่งคำสั่งของโมเดลขนาดใหญ่เป็นกุญแจสำคัญในการปรับปรุงประสิทธิภาพ Tencent Youtu Labs ร่วมมือกับ Shanghai Jiao Tong University ตีพิมพ์บทวิจารณ์โดยละเอียดที่ให้ข้อมูลเชิงลึกเกี่ยวกับการประเมินและการเลือกชุดข้อมูลการปรับแต่งคำสั่ง บทความยาว 10,000 คำนี้อิงตามเอกสารที่เกี่ยวข้องมากกว่า 400 ฉบับ ให้คำแนะนำที่ครอบคลุมสำหรับการปรับแต่งคำสั่งของแบบจำลองขนาดใหญ่จากคุณภาพข้อมูลสามมิติ ความหลากหลาย และความสำคัญ และชี้ให้เห็นถึงความท้าทายของการวิจัยที่มีอยู่และการพัฒนาในอนาคต ทิศทาง. บทความนี้ครอบคลุมถึงวิธีการประเมินผลที่หลากหลาย รวมถึงตัวบ่งชี้ที่ออกแบบด้วยมือ ตัวบ่งชี้ตามแบบจำลอง การให้คะแนนอัตโนมัติของ GPT และการประเมินด้วยตนเอง โดยมีจุดมุ่งหมายเพื่อช่วยให้นักวิจัยเลือกชุดข้อมูลที่เหมาะสมที่สุด และปรับปรุงประสิทธิภาพและความเสถียรของแบบจำลองขนาดใหญ่
ด้วยการอัพเกรดซ้ำอย่างต่อเนื่อง โมเดลขนาดใหญ่จะฉลาดขึ้น แต่เพื่อให้เข้าใจความต้องการของเราอย่างแท้จริง การปรับแต่งคำสั่งคือกุญแจสำคัญ ผู้เชี่ยวชาญจาก Tencent Youtu Lab และ Shanghai Jiao Tong University ได้ร่วมกันเผยแพร่บทวิจารณ์จำนวน 10,000 คำที่อภิปรายอย่างลึกซึ้งเกี่ยวกับการประเมินและการเลือกชุดข้อมูลการปรับแต่งคำสั่ง พร้อมเปิดเผยความลึกลับของวิธีปรับปรุงประสิทธิภาพของโมเดลขนาดใหญ่
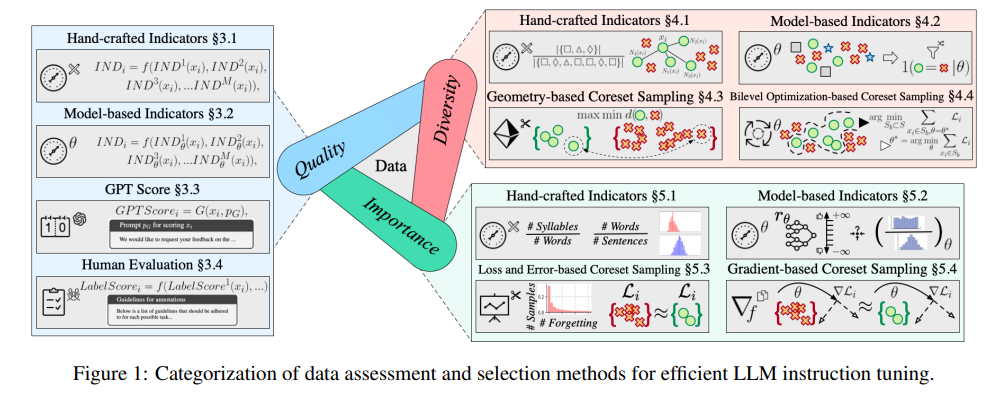
เป้าหมายของโมเดลขนาดใหญ่คือการเรียนรู้แก่นแท้ของการประมวลผลภาษาธรรมชาติ และการปรับคำสั่งเป็นขั้นตอนสำคัญในกระบวนการเรียนรู้ ผู้เชี่ยวชาญให้การวิเคราะห์เชิงลึกเกี่ยวกับวิธีการประเมินและเลือกชุดข้อมูลเพื่อให้แน่ใจว่าแบบจำลองขนาดใหญ่ทำงานได้ดีในงานที่หลากหลาย
การตรวจสอบนี้ไม่เพียงแต่มีความยาวที่น่าทึ่งเท่านั้น แต่ยังครอบคลุมเอกสารที่เกี่ยวข้องมากกว่า 400 ฉบับ ซึ่งให้คำแนะนำโดยละเอียดจากคุณภาพข้อมูล ความหลากหลาย และความสำคัญในสามมิติ
คุณภาพของข้อมูลส่งผลโดยตรงต่อประสิทธิผลของการปรับคำสั่ง ผู้เชี่ยวชาญได้เสนอวิธีการประเมินที่หลากหลาย รวมถึงตัวบ่งชี้ที่ออกแบบด้วยมือ ตัวบ่งชี้ตามแบบจำลอง การให้คะแนนอัตโนมัติ GPT และการประเมินด้วยตนเองที่ขาดไม่ได้
การประเมินความหลากหลายมุ่งเน้นไปที่ความสมบูรณ์ของชุดข้อมูล รวมถึงความหลากหลายของคำศัพท์ ความหมาย และการกระจายข้อมูลโดยรวม ด้วยชุดข้อมูลที่หลากหลาย โมเดลจึงสามารถสรุปสถานการณ์ต่างๆ ได้ดีขึ้น
การประเมินความสำคัญคือการเลือกตัวอย่างที่สำคัญที่สุดในการฝึกโมเดล ซึ่งไม่เพียงปรับปรุงประสิทธิภาพการฝึกอบรมเท่านั้น แต่ยังรับประกันความเสถียรและความแม่นยำของแบบจำลองเมื่อต้องเผชิญกับงานที่ซับซ้อน
แม้ว่าการวิจัยในปัจจุบันจะบรรลุผลลัพธ์บางอย่าง ผู้เชี่ยวชาญยังชี้ให้เห็นถึงความท้าทายที่มีอยู่ เช่น ความสัมพันธ์ที่อ่อนแอระหว่างการเลือกข้อมูลและประสิทธิภาพของแบบจำลอง และการขาดมาตรฐานที่เป็นหนึ่งเดียวในการประเมินคุณภาพของคำสั่ง
นับจากนี้ไป ผู้เชี่ยวชาญเรียกร้องให้มีการสร้างเกณฑ์มาตรฐานเฉพาะเพื่อประเมินโมเดลการปรับแต่งคำสั่ง ในขณะเดียวกันก็ปรับปรุงความสามารถในการตีความของไปป์ไลน์การคัดเลือกเพื่อปรับให้เข้ากับงานดาวน์สตรีมต่างๆ
การวิจัยโดย Tencent Youtu Lab และ Shanghai Jiao Tong University ไม่เพียงแต่ให้ทรัพยากรอันมีค่าแก่เราเท่านั้น แต่ยังชี้ให้เห็นทิศทางในการพัฒนาแบบจำลองขนาดใหญ่อีกด้วย ในขณะที่เทคโนโลยีก้าวหน้าอย่างต่อเนื่อง เราก็มีเหตุผลที่เชื่อได้ว่าโมเดลขนาดใหญ่จะมีความชาญฉลาดมากขึ้นและให้บริการมนุษย์ได้ดีขึ้น
ที่อยู่กระดาษ: https://arxiv.org/pdf/2408.02085
งานวิจัยนี้ให้คำแนะนำที่มีคุณค่าสำหรับการปรับแต่งคำสั่งโมเดลขนาดใหญ่ และวางรากฐานที่มั่นคงสำหรับการพัฒนาโมเดลขนาดใหญ่ในอนาคต เราหวังว่าจะได้รับผลการวิจัยที่คล้ายกันมากขึ้นในอนาคต ซึ่งจะส่งเสริมความก้าวหน้าอย่างต่อเนื่องของเทคโนโลยีแบบจำลองขนาดใหญ่และให้บริการมนุษยชาติได้ดียิ่งขึ้น