Tencent Youtu Lab และสถาบันอื่นๆ ได้เปิดตัว VITA รุ่นภาษาขนาดใหญ่แบบมัลติโมดัลรุ่นแรก ซึ่งสามารถประมวลผลวิดีโอ รูปภาพ ข้อความ และเสียงได้ในเวลาเดียวกัน และมอบประสบการณ์การโต้ตอบที่ราบรื่น การเกิดขึ้นของ VITA มีวัตถุประสงค์เพื่อชดเชยข้อบกพร่องของแบบจำลองภาษาขนาดใหญ่ที่มีอยู่ในการประมวลผลภาษาจีน ขึ้นอยู่กับแบบจำลอง Mixtral8×7B คำศัพท์ภาษาจีนได้รับการขยายและคำแนะนำแบบสองภาษาได้รับการปรับแต่งอย่างละเอียด ทำให้มีความเชี่ยวชาญในภาษาอังกฤษทั้งคู่ และพูดภาษาจีนได้คล่อง นี่เป็นความก้าวหน้าที่สำคัญสำหรับชุมชนโอเพ่นซอร์สในด้านความเข้าใจและการโต้ตอบหลายรูปแบบ
เมื่อเร็วๆ นี้ นักวิจัยจาก Tencent Youtu Lab และสถาบันอื่นๆ ได้เปิดตัว VITA โมเดลภาษาขนาดใหญ่แบบโอเพ่นซอร์สหลายโมดัลรุ่นแรก ซึ่งสามารถประมวลผลวิดีโอ รูปภาพ ข้อความ และเสียงได้ในเวลาเดียวกัน และประสบการณ์เชิงโต้ตอบก็อยู่ในระดับเฟิร์สคลาสเช่นกัน
แบบจำลอง VITA ถือกำเนิดขึ้นเพื่อเติมเต็มข้อบกพร่องของแบบจำลองภาษาขนาดใหญ่ในการประมวลผลภาษาจีน ขึ้นอยู่กับโมเดล Mixtral8×7B อันทรงพลัง คำศัพท์ภาษาจีนที่เพิ่มขึ้น และคำแนะนำสองภาษาที่ได้รับการปรับแต่ง ทำให้ VITA ไม่เพียงแต่เชี่ยวชาญภาษาอังกฤษเท่านั้น แต่ยังพูดภาษาจีนได้อย่างคล่องแคล่วอีกด้วย
คุณสมบัติหลัก:
ความเข้าใจหลายรูปแบบ: ความสามารถของ VITA ในการประมวลผลวิดีโอ รูปภาพ ข้อความ และเสียงนั้นไม่เคยมีมาก่อนในโมเดลโอเพ่นซอร์ส
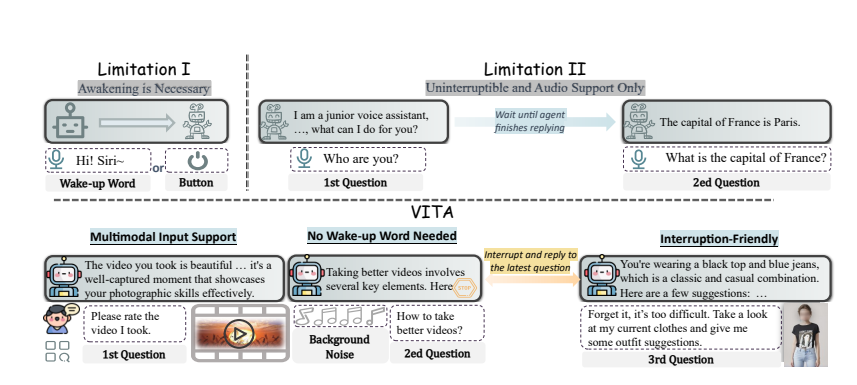
ปฏิสัมพันธ์ที่เป็นธรรมชาติ: ไม่จำเป็นต้องพูดว่า "เฮ้ VITA" ทุกครั้ง มันสามารถตอบสนองได้ตลอดเวลาเมื่อคุณพูด และแม้แต่ในขณะที่คุณกำลังพูดคุยกับผู้อื่น มันก็สามารถรักษาความสุภาพและไม่ขัดจังหวะได้ตามใจชอบ
ผู้บุกเบิกโอเพ่นซอร์ส: VITA เป็นก้าวสำคัญสำหรับชุมชนโอเพ่นซอร์สในการทำความเข้าใจและการโต้ตอบแบบหลายรูปแบบ โดยวางรากฐานสำหรับการวิจัยในภายหลัง
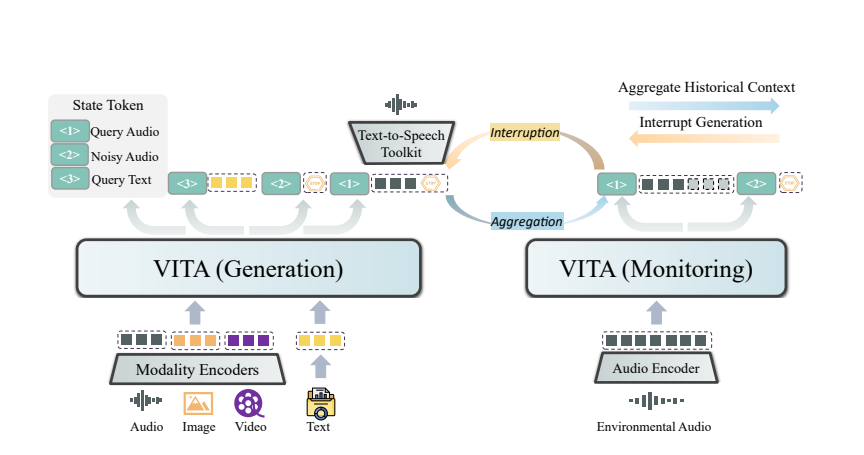
ความมหัศจรรย์ของ VITA มาจากการใช้งานแบบคู่ โมเดลหนึ่งมีหน้าที่รับผิดชอบในการสร้างการตอบสนองต่อคำถามของผู้ใช้ และอีกโมเดลหนึ่งจะติดตามอินพุตด้านสิ่งแวดล้อมอย่างต่อเนื่องเพื่อให้แน่ใจว่าทุกการโต้ตอบนั้นถูกต้องและทันเวลา
VITA ไม่เพียงแต่สามารถแชทเท่านั้น แต่ยังทำหน้าที่เป็นคู่สนทนาเมื่อคุณออกกำลังกาย และยังให้คำแนะนำเมื่อคุณเดินทางอีกด้วย นอกจากนี้ยังสามารถตอบคำถามตามรูปภาพหรือเนื้อหาวิดีโอที่คุณให้มา ซึ่งแสดงให้เห็นถึงการใช้งานจริงที่ทรงพลัง
แม้ว่า VITA จะแสดงศักยภาพที่ยอดเยี่ยม แต่ยังคงมีการพัฒนาในแง่ของการสังเคราะห์คำพูดทางอารมณ์และการสนับสนุนหลายรูปแบบ นักวิจัยวางแผนที่จะเปิดใช้งาน VITA รุ่นต่อไปเพื่อสร้างเสียงคุณภาพสูงจากวิดีโอและการป้อนข้อความ และแม้แต่สำรวจความเป็นไปได้ในการสร้างเสียงและวิดีโอคุณภาพสูงพร้อมกัน
โอเพ่นซอร์สของโมเดล VITA ไม่เพียงแต่เป็นชัยชนะทางเทคนิคเท่านั้น แต่ยังเป็นนวัตกรรมที่ลึกซึ้งในวิธีการโต้ตอบอัจฉริยะอีกด้วย ด้วยการวิจัยที่ลึกซึ้งยิ่งขึ้น เรามีเหตุผลที่เชื่อได้ว่า VITA จะนำประสบการณ์การโต้ตอบที่ชาญฉลาดและมีมนุษยธรรมมากขึ้นมาให้เรา
ที่อยู่กระดาษ: https://arxiv.org/pdf/2408.05211
โอเพ่นซอร์สของ VITA มอบทิศทางใหม่สำหรับการพัฒนาโมเดลภาษาขนาดใหญ่หลายรูปแบบ ฟังก์ชั่นที่ทรงพลังและประสบการณ์การโต้ตอบที่สะดวกสบายบ่งชี้ว่าปฏิสัมพันธ์ระหว่างมนุษย์กับคอมพิวเตอร์จะชาญฉลาดและมีมนุษยธรรมมากขึ้นในอนาคต เราหวังว่า VITA จะสร้างความก้าวหน้าที่ยิ่งใหญ่ยิ่งขึ้นในอนาคต และนำความสะดวกสบายมาสู่ชีวิตของผู้คนมากขึ้น