อาลีบาบาได้เปิดตัวโมเดลคำพูดแบบโอเพ่นซอร์สใหม่ Qwen2-Audio ซึ่งได้รับการปรับปรุงการรู้จำคำพูด การแปล และการวิเคราะห์เสียงให้ดีขึ้นอย่างมาก ฟังก์ชันและประสิทธิภาพเหนือกว่าผลิตภัณฑ์รุ่นก่อนหน้า Qwen-Audio และยังเหนือกว่าในการทดสอบเกณฑ์มาตรฐานหลายรายการ ขนาดใหญ่-v3. Qwen2-Audio รองรับหลายภาษาและมีเวอร์ชันพื้นฐานและเวอร์ชันที่ได้รับการปรับแต่งพร้อมคำแนะนำ ผู้ใช้สามารถถามคำถามผ่านเสียงและดำเนินการจดจำและวิเคราะห์เนื้อหาเสียง เช่น การกำหนดอายุและอารมณ์ของผู้พูดหรือวิเคราะห์เสียงต่างๆ ส่วนประกอบต่างๆ ในเสียง โมเดลนี้ใช้ภาษาที่เป็นธรรมชาติมากขึ้นสำหรับการฝึกอบรมล่วงหน้า ปรับปรุงความเข้าใจและความสามารถในการตอบสนองอย่างมาก และแนะนำโหมดการแชทด้วยเสียงและการวิเคราะห์เสียงสองโหมดเพื่อปรับปรุงความเป็นธรรมชาติของการโต้ตอบของผู้ใช้
เมื่อเร็วๆ นี้ อาลีบาบาได้เปิดตัวโมเดลคำพูดแบบโอเพ่นซอร์สใหม่ Qwen2-Audio โดยใช้ Qwen-Audio รุ่นนี้ไม่เพียงแต่ทำงานได้ดีในการรู้จำคำพูด การแปล และการวิเคราะห์เสียงเท่านั้น แต่ยังได้รับการปรับปรุงที่สำคัญในด้านฟังก์ชันการทำงานและประสิทธิภาพอีกด้วย Qwen2-Audio มีเวอร์ชันพื้นฐานและคำแนะนำเวอร์ชันที่ได้รับการปรับแต่ง ผู้ใช้สามารถถามคำถามเกี่ยวกับโมเดลเสียงผ่านเสียง และจดจำและวิเคราะห์เนื้อหาได้
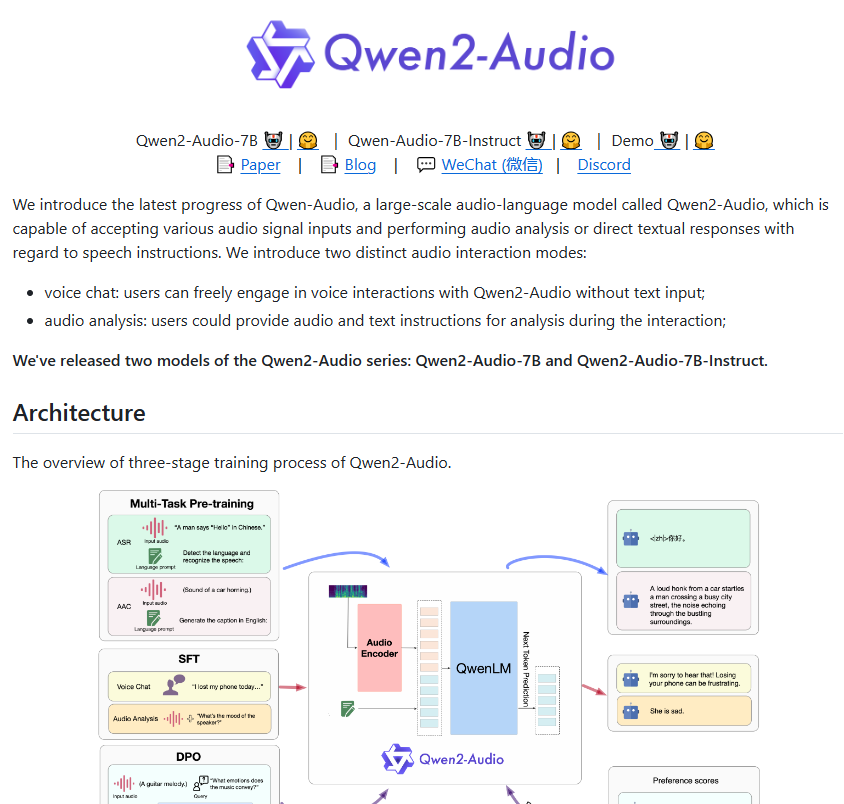
ตัวอย่างเช่น ผู้ใช้สามารถขอให้ผู้หญิงพูดได้ และ Qwen2-Audio สามารถระบุอายุของเธอหรือวิเคราะห์อารมณ์ของเธอได้ หากมีเสียงที่มีเสียงดังเข้ามา โมเดลก็สามารถวิเคราะห์องค์ประกอบเสียงต่างๆ ได้ Qwen2-Audio รองรับหลายภาษา รวมถึงภาษาจีน กวางตุ้ง ฝรั่งเศส อังกฤษ และญี่ปุ่น ซึ่งมอบความสะดวกสบายอย่างมากสำหรับการพัฒนาแอปพลิเคชันการวิเคราะห์ความรู้สึกและการแปล
ทางเข้าผลิตภัณฑ์: https://top.aibase.com/tool/qwen2-audio
เมื่อเปรียบเทียบกับ Qwen-Audio รุ่นแรก Qwen2-Audio ได้รับการปรับให้เหมาะสมที่สุดในด้านสถาปัตยกรรมและประสิทธิภาพ ในขั้นตอนก่อนการฝึกอบรม โมเดลใหม่นี้ใช้ภาษาที่เป็นธรรมชาติมากขึ้นเพื่อแทนที่ป้ายกำกับลำดับชั้นที่ซับซ้อนก่อนหน้านี้ การปรับปรุงนี้ทำให้แบบจำลองง่ายต่อการเข้าใจและตอบสนองต่องานต่างๆ และความสามารถในการวางนัยทั่วไปยังได้รับการปรับปรุงอย่างมีนัยสำคัญอีกด้วย
ความสามารถในการติดตามคำสั่งของ Qwen2-Audio ได้รับการปรับปรุงอย่างมาก และสามารถเข้าใจคำสั่งของผู้ใช้ได้แม่นยำยิ่งขึ้น ตัวอย่างเช่น เมื่อผู้ใช้ออกคำสั่ง "วิเคราะห์แนวโน้มทางอารมณ์ในเสียงนี้" Qwen2-Audio จะสามารถระบุอารมณ์ที่มีอยู่ในเสียงได้อย่างแม่นยำ นอกจากนี้ โมเดลยังแนะนำสองโหมด: การแชทด้วยเสียงและการวิเคราะห์เสียง ทำให้การโต้ตอบด้วยเสียงของผู้ใช้เป็นธรรมชาติมากขึ้น ในโหมดการวิเคราะห์เสียง Qwen2-Audio สามารถวิเคราะห์เสียงประเภทต่างๆ อย่างลึกซึ้งและให้ผลการวิเคราะห์ที่ละเอียดและแม่นยำ
เพื่อให้แน่ใจว่าเอาต์พุตของโมเดลตรงตามความคาดหวังของมนุษย์ Qwen2-Audio ยังแนะนำเทคโนโลยีขั้นสูง เช่น การปรับแต่งแบบละเอียดภายใต้การดูแล และการเพิ่มประสิทธิภาพการตั้งค่าโดยตรง โมเดลจะดูเป็นธรรมชาติและแม่นยำมากขึ้นเมื่อมีปฏิสัมพันธ์กับมนุษย์
ในแง่ของการทดสอบประสิทธิภาพ Qwen2-Audio ทำงานได้ดีในการทดสอบเกณฑ์มาตรฐานกระแสหลักหลายรายการ โดยเฉพาะอย่างยิ่งในความแม่นยำของการรู้จำเสียงและการแปล ซึ่งเหนือกว่า Whisper-large-v3 ของ OpenAI ประสิทธิภาพของโมเดลใหม่นี้ไม่เพียงดึงดูดความสนใจอย่างกว้างขวางในอุตสาหกรรม แต่ยังเป็นการประกาศถึงอนาคตใหม่สำหรับเทคโนโลยีเสียงอีกด้วย
ไฮไลท์:
Qwen2-Audio เป็นโมเดลคำพูดแบบโอเพ่นซอร์สล่าสุดของอาลีบาบา ซึ่งรองรับหลายภาษา และมีความสามารถในการจดจำและวิเคราะห์อันทรงพลัง
เมื่อเปรียบเทียบกับรุ่นก่อนหน้า Qwen2-Audio ได้รับการปรับปรุงประสิทธิภาพและสถาปัตยกรรมอย่างมาก ปรับปรุงความสามารถในการทำความเข้าใจและตอบสนอง
ในการทดสอบประสิทธิภาพหลายครั้ง Qwen2-Audio มีประสิทธิภาพเหนือกว่า Whisper ของ OpenAI ซึ่งแสดงให้เห็นถึงความสามารถในการแข่งขันที่แข็งแกร่ง
โอเพ่นซอร์สของ Qwen2-Audio จะส่งเสริมการพัฒนาสาขาเทคโนโลยีเสียง มอบเครื่องมืออันทรงพลังแก่นักพัฒนา และส่งเสริมให้เกิดแอปพลิเคชันที่เป็นนวัตกรรมมากขึ้น ข้อดีของการรองรับหลายภาษาและประสิทธิภาพทำให้เป็นทิศทางสำคัญสำหรับการพัฒนาเทคโนโลยีเสียงในอนาคต รอคอยที่จะประยุกต์ใช้ Qwen2-Audio ในสถานการณ์เพิ่มเติม