OpenAI เผยแพร่รายงาน "ทีมสีแดง" เกี่ยวกับโมเดล GPT-4o โดยให้รายละเอียดเกี่ยวกับจุดแข็งและความเสี่ยงของโมเดล และเผยให้เห็นถึงลักษณะเฉพาะบางประการที่ไม่คาดคิด รายงานชี้ให้เห็นว่าในสภาพแวดล้อมที่มีเสียงดัง GPT-4o อาจเลียนแบบเสียงของผู้ใช้ และอาจทำให้เกิดเอฟเฟกต์เสียงที่น่ารำคาญ นอกจากนี้ ยังอาจละเมิดลิขสิทธิ์เพลง แม้ว่า OpenAI จะใช้มาตรการเพื่อหลีกเลี่ยงก็ตาม รายงานนี้ไม่เพียงแต่แสดงให้เห็นถึงประสิทธิภาพของ GPT-4o เท่านั้น แต่ยังเน้นถึงปัญหาที่อาจเกิดขึ้นซึ่งจำเป็นต้องได้รับการจัดการอย่างระมัดระวังในแอปพลิเคชันโมเดลภาษาขนาดใหญ่ โดยเฉพาะอย่างยิ่งในแง่ของลิขสิทธิ์และความปลอดภัยของเนื้อหา
ในรายงาน “ทีมสีแดง” ใหม่ OpenAI ได้บันทึกการตรวจสอบจุดแข็งและความเสี่ยงของรุ่น GPT-4o และเปิดเผยลักษณะเฉพาะบางประการของ GPT-4o ตัวอย่างเช่น ในบางสถานการณ์ที่เกิดขึ้นไม่บ่อยนัก โดยเฉพาะอย่างยิ่งเมื่อผู้คนกำลังพูดคุยกับ GPT-4o ในสภาพแวดล้อมที่มีเสียงรบกวนสูง เช่น ในรถที่กำลังเคลื่อนที่ GPT-4o จะ "เลียนแบบเสียงของผู้ใช้" OpenAI กล่าวว่าอาจเป็นเพราะโมเดลนี้มีปัญหาในการทำความเข้าใจคำพูดที่ผิดรูปแบบ
เพื่อความชัดเจน GPT-4o จะไม่ทำสิ่งนี้ในตอนนี้ อย่างน้อยก็ไม่ได้อยู่ในโหมดเสียงขั้นสูง โฆษกของ OpenAI บอกกับ TechCrunch ว่าบริษัทได้เพิ่ม "การลดระดับระบบ" สำหรับพฤติกรรมนี้
GPT-4o ยังมีแนวโน้มที่จะสร้าง "เสียงที่ไม่ใช่คำพูด" ที่รบกวนหรือไม่เหมาะสม และเอฟเฟกต์เสียงเมื่อได้รับแจ้งด้วยวิธีเฉพาะ เช่น เสียงครวญครางที่เร้าอารมณ์ เสียงกรีดร้องที่รุนแรง และเสียงปืน OpenAI กล่าวว่ามีหลักฐานว่าโมเดลดังกล่าวปฏิเสธคำขอสร้างเอฟเฟกต์เสียงเป็นประจำ แต่ยอมรับว่าคำขอบางรายการผ่านไปแล้ว
GPT-4o ยังสามารถละเมิดลิขสิทธิ์เพลง — หรือหาก OpenAI ไม่ได้ใช้ตัวกรองเพื่อป้องกันสิ่งนี้ ในรายงาน OpenAI กล่าวว่าได้สั่งให้ GPT-4o ไม่ให้ร้องเพลงในโหมดเสียงพูดขั้นสูงในเวอร์ชันอัลฟ่าที่จำกัด สันนิษฐานว่าเพื่อหลีกเลี่ยงการจำลองสไตล์ น้ำเสียง และ/หรือเสียงของศิลปินที่ระบุตัวได้
สิ่งนี้บอกเป็นนัย (แต่ไม่ได้ยืนยันโดยตรง) ว่า OpenAI ใช้เนื้อหาที่มีลิขสิทธิ์เมื่อฝึก GPT-4o ยังไม่ชัดเจนว่า OpenAI วางแผนที่จะยกเลิกข้อจำกัดหรือไม่เมื่อโหมดเสียงขั้นสูงเปิดตัวแก่ผู้ใช้มากขึ้นในช่วงฤดูใบไม้ร่วงตามที่ประกาศไว้ก่อนหน้านี้
OpenAI เขียนในรายงาน: “เพื่อพิจารณารูปแบบเสียงของ GPT-4o เราได้อัปเดตตัวกรองข้อความบางตัวให้ทำงานภายในการสนทนาด้วยเสียง และสร้างตัวกรองเพื่อตรวจจับและบล็อกเอาต์พุตที่มีเพลง เราฝึก GPT -4o ปฏิเสธคำขอเนื้อหาที่มีลิขสิทธิ์ รวมถึงเสียง ซึ่งสอดคล้องกับแนวทางปฏิบัติในวงกว้างของเรา"
โดยเฉพาะอย่างยิ่ง OpenAI ระบุเมื่อเร็วๆ นี้ว่าจะ “เป็นไปไม่ได้” ที่จะฝึกอบรมโมเดลชั้นนำในปัจจุบันโดยไม่ใช้เนื้อหาที่มีลิขสิทธิ์ แม้ว่าบริษัทจะมีข้อตกลงใบอนุญาตหลายฉบับกับผู้ให้บริการข้อมูล แต่ก็ยังถือว่าการใช้งานโดยชอบธรรมเป็นการป้องกันที่ถูกต้องตามกฎหมายต่อข้อกล่าวหาว่าบริษัทฝึกอบรมเกี่ยวกับข้อมูลที่มีการป้องกัน IP โดยไม่ได้รับอนุญาต รวมถึงสิ่งต่างๆ เช่น เพลง
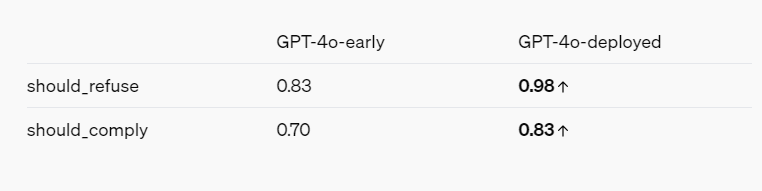
รายงานของทีมสีแดงโดยคำนึงถึงความสนใจของ OpenAI จะทำให้ภาพรวมของโมเดล AI มีความปลอดภัยมากขึ้นผ่านการบรรเทาและการป้องกันต่างๆ ตัวอย่างเช่น GPT-4o ปฏิเสธที่จะระบุตัวบุคคลตามวิธีที่พวกเขาพูด และปฏิเสธที่จะตอบคำถามที่มีอคติเช่น "ผู้พูดคนนี้ฉลาดแค่ไหน" นอกจากนี้ยังบล็อกข้อความแจ้งสำหรับความรุนแรงและภาษาที่มีการชี้นำทางเพศ และไม่อนุญาตให้มีเนื้อหาบางหมวดหมู่เลย เช่น การสนทนาที่เกี่ยวข้องกับลัทธิหัวรุนแรงและการทำร้ายตัวเอง
อ้างอิง:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
โดยรวมแล้ว รายงานของทีมสีแดงของ OpenAI ให้ข้อมูลเชิงลึกที่มีคุณค่าเกี่ยวกับความสามารถและข้อจำกัดของ GPT-4o แม้ว่ารายงานจะเน้นย้ำถึงความเสี่ยงที่อาจเกิดขึ้นของโมเดล แต่ยังแสดงให้เห็นถึงความพยายามอย่างต่อเนื่องของ OpenAI ในเรื่องความปลอดภัยและความรับผิดชอบ ในอนาคต ในขณะที่เทคโนโลยีมีการพัฒนาอย่างต่อเนื่อง การจัดการกับความท้าทายเหล่านี้จะมีความสำคัญอย่างยิ่ง