โมเดลภาษาขนาดใหญ่ (LLM) เผชิญกับความท้าทายในการทำความเข้าใจข้อความขนาดยาว และขนาดหน้าต่างบริบทจะจำกัดความสามารถในการประมวลผล เพื่อแก้ปัญหานี้ นักวิจัยได้พัฒนาการทดสอบเกณฑ์มาตรฐาน LooGLE เพื่อประเมินความสามารถในการทำความเข้าใจบริบทระยะยาวของ LLM LooGLE ประกอบด้วยเอกสารที่ยาวเป็นพิเศษ 776 ฉบับ (โดยเฉลี่ย 19.3,000 คำ) ที่เผยแพร่หลังอินสแตนซ์การทดสอบปี 2022 และ 6,448 รายการ ซึ่งครอบคลุมหลายสาขา โดยมีเป้าหมายเพื่อประเมินความสามารถของโมเดลในการทำความเข้าใจและประมวลผลข้อความขนาดยาวอย่างครอบคลุมมากขึ้น เกณฑ์มาตรฐานนี้จะประเมินประสิทธิภาพของ LLM ที่มีอยู่ และให้ข้อมูลอ้างอิงที่มีคุณค่าสำหรับการพัฒนาโมเดลในอนาคต
ในด้านการประมวลผลภาษาธรรมชาติ การทำความเข้าใจบริบทแบบยาวถือเป็นเรื่องท้าทายมาโดยตลอด แม้ว่าโมเดลภาษาขนาดใหญ่ (LLM) จะทำงานได้ดีกับงานภาษาต่างๆ แต่มักถูกจำกัดเมื่อประมวลผลข้อความที่เกินขนาดของหน้าต่างบริบท เพื่อเอาชนะข้อจำกัดนี้ นักวิจัยได้ทำงานอย่างหนักเพื่อปรับปรุงความสามารถของ LLM ในการทำความเข้าใจข้อความขนาดยาว ซึ่งไม่เพียงแต่มีความสำคัญสำหรับการวิจัยทางวิชาการเท่านั้น แต่ยังรวมถึงสถานการณ์การใช้งานในโลกแห่งความเป็นจริงด้วย เช่น ความเข้าใจความรู้เฉพาะโดเมน การสร้างบทสนทนาและเรื่องราวขนาดยาว หรือการสร้างโค้ด ฯลฯ ก็มีความสำคัญเช่นกัน
ในการศึกษานี้ ผู้เขียนเสนอการทดสอบเกณฑ์มาตรฐานใหม่ - LooGLE (การประเมินภาษาทั่วไปตามบริบทแบบยาว) ซึ่งได้รับการออกแบบมาเป็นพิเศษเพื่อประเมินความสามารถในการทำความเข้าใจบริบทแบบยาวของ LLM เกณฑ์มาตรฐานนี้ประกอบด้วยเอกสารที่ยาวเป็นพิเศษ 776 ฉบับหลังจากปี 2022 แต่ละเอกสารประกอบด้วยคำโดยเฉลี่ย 19.3,000 คำ และมีตัวอย่างการทดสอบ 6,448 รายการ ซึ่งครอบคลุมหลายสาขา เช่น วิชาการ ประวัติศาสตร์ กีฬา การเมือง ศิลปะ กิจกรรม และความบันเทิง เป็นต้น
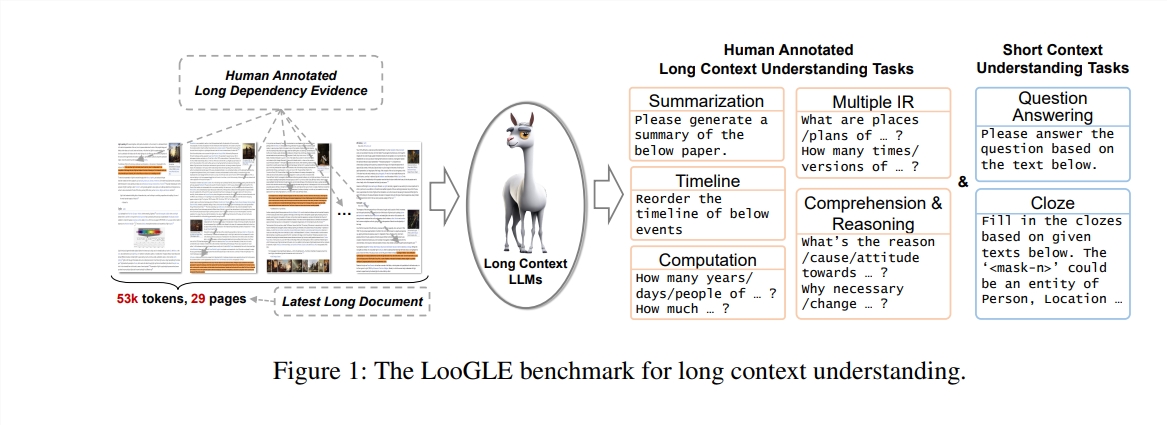
คุณสมบัติของ LoGLE
เอกสารจริงที่ยาวเป็นพิเศษ: ความยาวของเอกสารใน ooGLE เกินกว่าขนาดหน้าต่างบริบทของ LLM อย่างมาก ซึ่งต้องการให้โมเดลสามารถจดจำและเข้าใจข้อความที่ยาวขึ้นได้
ออกแบบงานการขึ้นต่อกันแบบยาวและระยะสั้นด้วยตนเอง: การทดสอบเกณฑ์มาตรฐานประกอบด้วยงานหลัก 7 งาน รวมถึงงานการขึ้นต่อกันแบบสั้นและงานการขึ้นต่อกันแบบยาว เพื่อประเมินความสามารถของ LLM ในการทำความเข้าใจเนื้อหาของการขึ้นต่อกันแบบยาวและแบบสั้น
เอกสารค่อนข้างใหม่: เอกสารทั้งหมดเผยแพร่หลังปี 2022 ซึ่งทำให้มั่นใจได้ว่า LLM สมัยใหม่ส่วนใหญ่จะไม่ถูกเปิดเผยกับเอกสารเหล่านี้ในระหว่างการฝึกอบรมก่อนการฝึกอบรม ช่วยให้ประเมินความสามารถในการเรียนรู้ตามบริบทได้แม่นยำยิ่งขึ้น
ข้อมูลทั่วไปแบบข้ามโดเมน: ข้อมูลเกณฑ์มาตรฐานมาจากเอกสารโอเพ่นซอร์สยอดนิยม เช่น เอกสาร arXiv บทความ Wikipedia สคริปต์ภาพยนตร์และทีวี เป็นต้น
นักวิจัยได้ทำการประเมินที่ครอบคลุมของ LLM ที่ล้ำสมัยจำนวน 8 แห่ง และผลลัพธ์เผยให้เห็นข้อค้นพบที่สำคัญดังต่อไปนี้:
โมเดลเชิงพาณิชย์มีประสิทธิภาพเหนือกว่าโมเดลโอเพ่นซอร์สในด้านประสิทธิภาพ
LLM ทำงานได้ดีกับงานที่ต้องพึ่งพาระยะสั้น แต่มีความท้าทายในงานที่ต้องพึ่งพาระยะยาวที่ซับซ้อนกว่า
วิธีการที่ใช้การเรียนรู้บริบทและห่วงโซ่ความคิดช่วยให้เข้าใจบริบทแบบยาวมีการปรับปรุงอย่างจำกัด
เทคนิคที่ยึดตามการดึงข้อมูลแสดงให้เห็นถึงข้อได้เปรียบที่สำคัญในการตอบคำถามสั้นๆ ในขณะที่กลยุทธ์ในการขยายความยาวของหน้าต่างบริบทผ่านสถาปัตยกรรม Transformer ที่ปรับให้เหมาะสมหรือการเข้ารหัสตำแหน่งมีผลกระทบที่จำกัดต่อการทำความเข้าใจบริบทที่ยาวนาน
เกณฑ์มาตรฐาน LooGLE ไม่เพียงแต่ให้แผนการประเมินที่เป็นระบบและครอบคลุมสำหรับการประเมิน LLM ในบริบทแบบยาวเท่านั้น แต่ยังให้คำแนะนำสำหรับการพัฒนาแบบจำลองในอนาคตด้วยความสามารถ "การทำความเข้าใจในบริบทแบบยาวที่แท้จริง" รหัสการประเมินผลทั้งหมดได้รับการเผยแพร่บน GitHub เพื่อใช้อ้างอิงและใช้งานโดยชุมชนการวิจัย
ที่อยู่กระดาษ: https://arxiv.org/pdf/2311.04939
ที่อยู่รหัส: https://github.com/bigai-nlco/LooGLE
เกณฑ์มาตรฐาน LooGLE เป็นเครื่องมือสำคัญในการประเมินและปรับปรุงความสามารถในการทำความเข้าใจข้อความขนาดยาวของ LLM และผลการวิจัยมีความสำคัญอย่างยิ่งในการส่งเสริมการพัฒนาด้านการประมวลผลภาษาธรรมชาติ ทิศทางการปรับปรุงที่เสนอโดยนักวิจัยนั้นคุ้มค่าแก่ความสนใจ ฉันเชื่อว่า LLM ที่ทรงพลังมากขึ้นจะปรากฏขึ้นในอนาคตเพื่อจัดการกับข้อความขนาดยาวได้ดีขึ้น