Apple ร่วมกับมหาวิทยาลัย Washington และสถาบันอื่นๆ ได้เปิดตัวโมเดลภาษาอันทรงพลังที่เรียกว่า DCLM ในรูปแบบโอเพ่นซอร์ส โดยมีขนาดพารามิเตอร์ 700 ล้านและข้อมูลการฝึกอบรมจำนวนมหาศาลถึง 2.5 ล้านล้านโทเค็นข้อมูล DCLM ไม่เพียงแต่เป็นโมเดลภาษาที่มีประสิทธิภาพเท่านั้น แต่ที่สำคัญกว่านั้น ยังมีเครื่องมือที่เรียกว่า "การแข่งขันชุดข้อมูล" (DataComp) สำหรับการเพิ่มประสิทธิภาพชุดข้อมูลของโมเดลภาษา นวัตกรรมนี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพของโมเดลเท่านั้น แต่ยังให้วิธีการและมาตรฐานใหม่สำหรับการวิจัยโมเดลภาษาซึ่งสมควรได้รับความสนใจ
ล่าสุด ทีมปัญญาประดิษฐ์ของ Apple ร่วมมือกับสถาบันหลายแห่ง เช่น มหาวิทยาลัยวอชิงตัน เพื่อเปิดตัวโมเดลภาษาโอเพ่นซอร์สที่เรียกว่า DCLM โมเดลนี้มีพารามิเตอร์ 700 ล้านพารามิเตอร์และใช้โทเค็นข้อมูลมากถึง 2.5 ล้านล้านโทเค็นระหว่างการฝึกอบรมเพื่อช่วยให้เราเข้าใจและสร้างภาษาได้ดีขึ้น
แล้ว Language Model คืออะไร พูดง่ายๆ ก็คือเป็นโปรแกรมที่สามารถวิเคราะห์และสร้างภาษาช่วยให้เราทำงานต่างๆ ได้สำเร็จ เช่น การแปล การสร้างข้อความ และการวิเคราะห์ความรู้สึก เพื่อให้โมเดลเหล่านี้ทำงานได้ดีขึ้น เราจำเป็นต้องมีชุดข้อมูลที่มีคุณภาพ อย่างไรก็ตาม การได้รับและจัดระเบียบข้อมูลนี้ไม่ใช่เรื่องง่าย เนื่องจากเราจำเป็นต้องกรองเนื้อหาที่ไม่เกี่ยวข้องหรือเป็นอันตรายออก และลบข้อมูลที่ซ้ำกัน
เพื่อจัดการกับความท้าทายนี้ ทีมวิจัยของ Apple ได้เปิดตัว DataComp for Language Models (DCLM) ซึ่งเป็นเครื่องมือเพิ่มประสิทธิภาพชุดข้อมูลสำหรับโมเดลภาษา พวกเขาเพิ่งเปิดซอร์สโมเดล DCIM และชุดข้อมูลบนแพลตฟอร์ม Hugging Face เวอร์ชันโอเพ่นซอร์ส ได้แก่ DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 และ dclm-baseline-1.0-parquet นักวิจัยสามารถทำการทดลองจำนวนมากผ่านแพลตฟอร์มนี้ได้ และค้นหาแนวทางแก้ไขที่ดีที่สุด
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
จุดแข็งหลักของ DCLM คือขั้นตอนการทำงานที่มีโครงสร้าง นักวิจัยสามารถเลือกโมเดลที่มีขนาดแตกต่างกันได้ตามความต้องการ ตั้งแต่ 412 ล้านถึง 700 ล้านพารามิเตอร์ และยังสามารถทดลองด้วยวิธีการจัดการข้อมูลต่างๆ เช่น การขจัดข้อมูลซ้ำซ้อนและการกรอง ด้วยการทดลองที่เป็นระบบเหล่านี้ นักวิจัยสามารถประเมินคุณภาพของชุดข้อมูลต่างๆ ได้อย่างชัดเจน สิ่งนี้ไม่เพียงวางรากฐานสำหรับการวิจัยในอนาคต แต่ยังช่วยให้เราเข้าใจวิธีปรับปรุงประสิทธิภาพของโมเดลด้วยการปรับปรุงชุดข้อมูล
ตัวอย่างเช่น เมื่อใช้ชุดข้อมูลเกณฑ์มาตรฐานที่กำหนดโดย DCLM ทีมวิจัยได้ฝึกอบรมโมเดลภาษาที่มีพารามิเตอร์ 700 ล้านพารามิเตอร์ และได้รับความแม่นยำ 5 ช็อตที่ 64% ในการทดสอบเกณฑ์มาตรฐาน MMLU ซึ่งเพิ่มขึ้น 6.6 เมื่อเทียบกับรุ่นก่อนหน้า คะแนนเปอร์เซ็นต์สูงสุดและใช้ทรัพยากรการคำนวณน้อยลง 40% ประสิทธิภาพของโมเดลพื้นฐาน DCLM ยังเทียบได้กับ Mistral-7B-v0.3 และ Llama38B ซึ่งต้องใช้ทรัพยากรการประมวลผลมากกว่ามาก
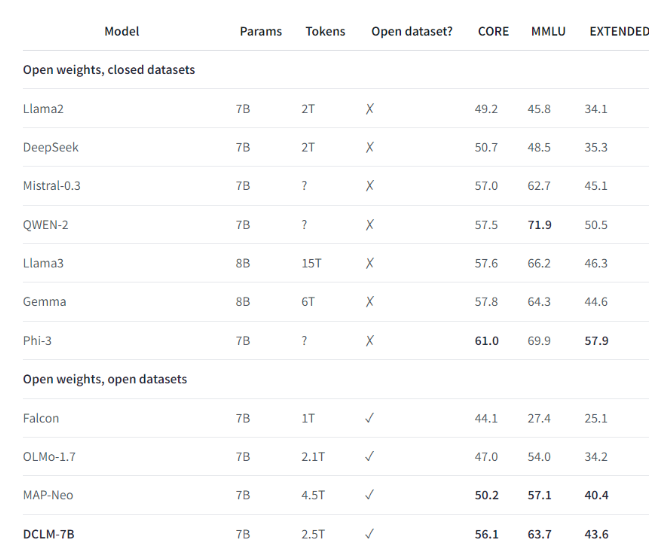
การเปิดตัว DCLM ถือเป็นเกณฑ์มาตรฐานใหม่สำหรับการวิจัยโมเดลภาษา ช่วยให้นักวิทยาศาสตร์สามารถปรับปรุงประสิทธิภาพของโมเดลอย่างเป็นระบบ ในขณะเดียวกันก็ลดทรัพยากรคอมพิวเตอร์ที่จำเป็นลงด้วย
ไฮไลท์:
1️⃣ Apple AI ร่วมมือกับสถาบันหลายแห่งเพื่อเปิดตัว DCLM โดยสร้างโมเดลภาษาโอเพ่นซอร์สที่ทรงพลัง
2️⃣ DCLM มอบเครื่องมือเพิ่มประสิทธิภาพชุดข้อมูลที่เป็นมาตรฐานเพื่อช่วยให้นักวิจัยทำการทดลองที่มีประสิทธิผล
3️⃣ โมเดลใหม่สร้างความก้าวหน้าอย่างมากในการทดสอบที่สำคัญพร้อมทั้งลดความต้องการทรัพยากรการคำนวณ
โดยรวมแล้ว โอเพ่นซอร์สของ DCLM ได้เพิ่มพลังใหม่ให้กับสาขาการวิจัยโมเดลภาษา และเครื่องมือเพิ่มประสิทธิภาพโมเดลและชุดข้อมูลที่มีประสิทธิภาพนั้น คาดว่าจะช่วยส่งเสริมการพัฒนาที่รวดเร็วยิ่งขึ้นในสาขานี้ และส่งเสริมการกำเนิดของโมเดลภาษาที่ทรงพลังและมีประสิทธิภาพมากขึ้น ในอนาคต เราคาดหวังให้ DCLM นำเสนอผลการวิจัยที่น่าประหลาดใจมากขึ้น