ทีม Alibaba Tongyi Qianwen เปิดตัวซีรีส์ Qwen2 ของโมเดลโอเพ่นซอร์ส ซีรีส์นี้ประกอบด้วยโมเดลก่อนการฝึกอบรมและการปรับแต่งคำสั่ง 5 ขนาด จำนวนพารามิเตอร์และประสิทธิภาพได้รับการปรับปรุงอย่างมีนัยสำคัญเมื่อเทียบกับ Qwen1.5 รุ่นก่อนหน้า ซีรีส์ Qwen2 ยังได้สร้างความก้าวหน้าครั้งใหญ่ในด้านความสามารถหลายภาษา โดยรองรับ 27 ภาษา นอกเหนือจากภาษาอังกฤษและจีน ในแง่ของความเข้าใจภาษาธรรมชาติ การเขียนโค้ด ความสามารถทางคณิตศาสตร์ ฯลฯ โมเดลขนาดใหญ่ (พารามิเตอร์ 70B+) ทำงานได้ดี โดยเฉพาะโมเดล Qwen2-72B เหนือกว่ารุ่นก่อนหน้าในด้านประสิทธิภาพและจำนวนพารามิเตอร์ การเปิดตัวครั้งนี้ถือเป็นก้าวใหม่ของเทคโนโลยีปัญญาประดิษฐ์ โดยมอบความเป็นไปได้ที่กว้างขึ้นสำหรับการประยุกต์ใช้ AI ทั่วโลกและเชิงพาณิชย์
เมื่อเช้าวันนี้ ทีมอาลีบาบา Tongyi Qianwen ได้เปิดตัวโมเดลโอเพ่นซอร์สซีรีส์ Qwen2 ซีรีส์ของโมเดลนี้ประกอบด้วยโมเดลที่ได้รับการฝึกอบรมล่วงหน้าและคำแนะนำอย่างละเอียดใน 5 ขนาด: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B และ Qwen2-72B ข้อมูลสำคัญแสดงให้เห็นว่าจำนวนพารามิเตอร์และประสิทธิภาพของรุ่นเหล่านี้ได้รับการปรับปรุงอย่างมีนัยสำคัญเมื่อเทียบกับ Qwen1.5 รุ่นก่อนหน้า
สำหรับความสามารถหลายภาษาของรุ่นนี้ ซีรีส์ Qwen2 ได้ทุ่มเทความพยายามอย่างมากในการเพิ่มปริมาณและคุณภาพของชุดข้อมูล ครอบคลุมภาษาอื่นๆ อีก 27 ภาษา นอกเหนือจากภาษาอังกฤษและจีน หลังจากการทดสอบเปรียบเทียบ โมเดลขนาดใหญ่ (70B + พารามิเตอร์) ทำงานได้ดีในด้านความเข้าใจภาษาธรรมชาติ การเขียนโค้ด ความสามารถทางคณิตศาสตร์ ฯลฯ โมเดล Qwen2-72B เหนือกว่ารุ่นก่อนหน้าในแง่ของประสิทธิภาพและจำนวนพารามิเตอร์
โมเดล Qwen2 ไม่เพียงแต่แสดงให้เห็นถึงความสามารถที่แข็งแกร่งในการประเมินโมเดลภาษาพื้นฐานเท่านั้น แต่ยังให้ผลลัพธ์ที่น่าประทับใจในการประเมินโมเดลการปรับแต่งคำสั่งอีกด้วย ความสามารถหลายภาษาทำงานได้ดีในการทดสอบเกณฑ์มาตรฐาน เช่น M-MMLU และ MGSM ซึ่งแสดงให้เห็นถึงศักยภาพอันทรงพลังของโมเดลการปรับแต่งคำสั่ง Qwen2
โมเดลซีรีส์ Qwen2 ที่เปิดตัวในครั้งนี้ถือเป็นอีกระดับของเทคโนโลยีปัญญาประดิษฐ์ ซึ่งมอบความเป็นไปได้ที่กว้างขึ้นสำหรับแอปพลิเคชัน AI ระดับโลกและเชิงพาณิชย์ เมื่อมองไปสู่อนาคต Qwen2 จะขยายขนาดของโมเดลและความสามารถหลายรูปแบบเพิ่มเติม เพื่อเร่งการพัฒนาสาขา AI แบบโอเพ่นซอร์ส
ข้อมูลรุ่นซีรีส์ Qwen2 ประกอบด้วยรุ่นพื้นฐานและรุ่นปรับแต่งคำสั่ง 5 ขนาด รวมถึง Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B และ Qwen2-72B เราอธิบายข้อมูลสำคัญสำหรับแต่ละรุ่นในตารางด้านล่าง:
รุ่น Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# พารามิเตอร์ 049 ล้าน 154 ล้าน 707B57.41B72.71B# Non-Emb พารามิเตอร์ 035 ล้าน 131B598 ล้าน 5632 ล้าน 7021B การประกันคุณภาพจริงๆ จริงๆ ของ true true tie ฝัง true จริง เท็จ เท็จ เท็จ บริบทเท็จ ความยาว 32,000 32,000 128,000 64,000 128,000โดยเฉพาะใน Qwen1.5 มีเพียง Qwen1.5-32B และ Qwen1.5-110B เท่านั้นที่ใช้ Group Query Attention (GQA) ครั้งนี้ เราใช้ GQA กับโมเดลทุกขนาด เพื่อให้ได้รับประโยชน์จากความเร็วที่เร็วขึ้นและขนาดหน่วยความจำที่เล็กลงในการอนุมานโมเดล สำหรับโมเดลขนาดเล็ก เราต้องการใช้การผูกแบบฝัง เนื่องจากการฝังแบบเบาบางขนาดใหญ่ถือเป็นส่วนใหญ่ของพารามิเตอร์ทั้งหมดของโมเดล
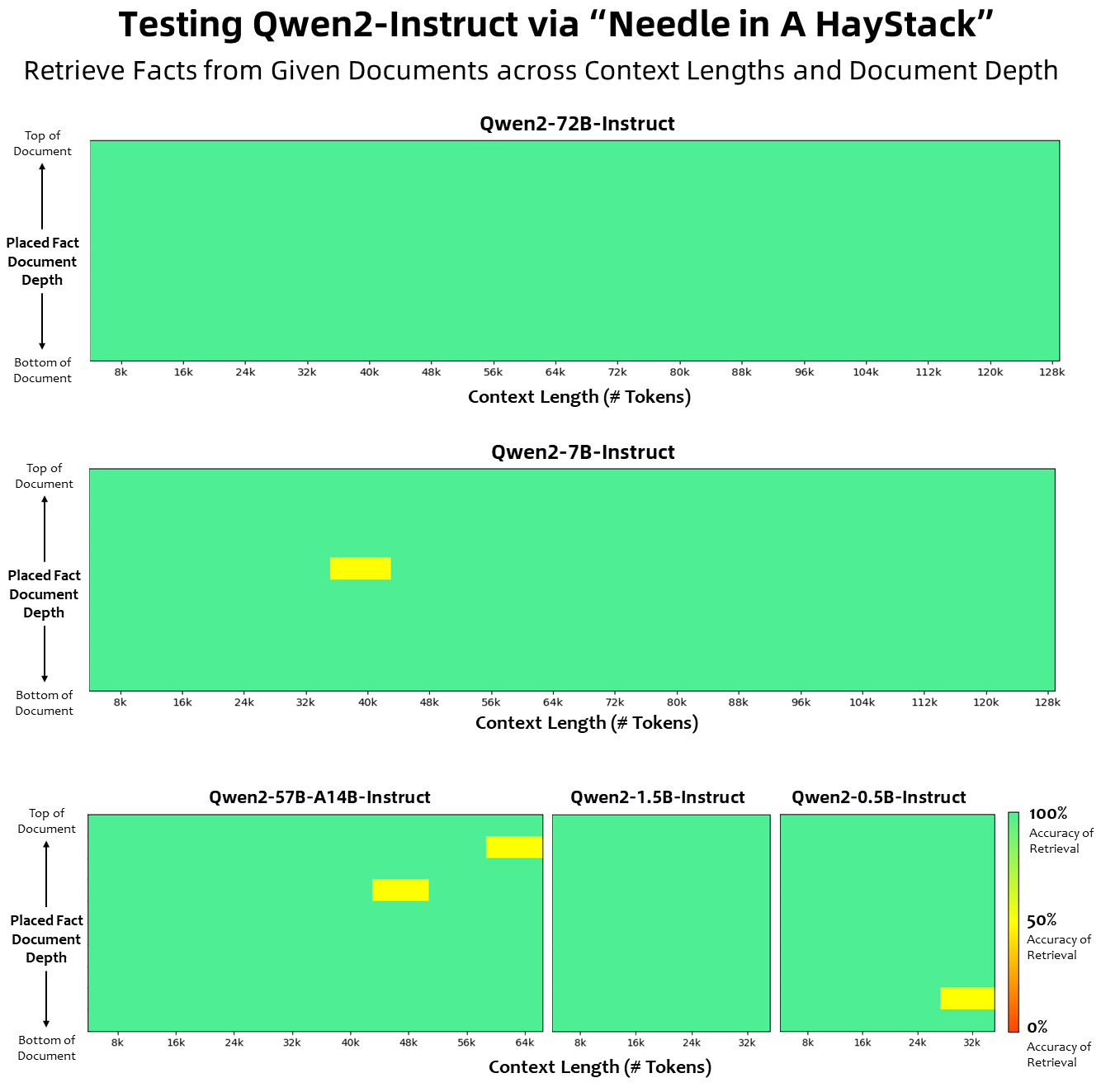
ในแง่ของความยาวบริบท โมเดลภาษาพื้นฐานทั้งหมดได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับข้อมูลความยาวบริบทของโทเค็น 32K และเราสังเกตเห็นความสามารถในการคาดการณ์ที่น่าพอใจสูงถึง 128K ในการประเมิน PPL อย่างไรก็ตาม สำหรับโมเดลที่ได้รับการปรับแต่งคำสั่ง เราไม่พอใจกับการประเมิน PPL เท่านั้น เราต้องการให้โมเดลสามารถเข้าใจบริบทที่ยาวได้อย่างถูกต้องและทำงานให้สำเร็จได้ ในตาราง เราแสดงรายการความสามารถด้านความยาวบริบทของโมเดลการปรับคำสั่ง ตามที่ประเมินโดยการประเมินผลงาน Needlein a Haystack เป็นที่น่าสังเกตว่าเมื่อเสริมด้วย YARN ทั้งโมเดล Qwen2-7B-Instruct และ Qwen2-72B-Instruct จะแสดงความสามารถที่น่าประทับใจ และสามารถรองรับความยาวบริบทได้สูงสุด 128K โทเค็น
เราได้ใช้ความพยายามอย่างมากในการเพิ่มปริมาณและคุณภาพของชุดข้อมูลก่อนการฝึกอบรมและการปรับแต่งคำแนะนำซึ่งครอบคลุมหลายภาษา นอกเหนือจากภาษาอังกฤษและจีน เพื่อเพิ่มความสามารถในหลายภาษา แม้ว่าโมเดลภาษาขนาดใหญ่มีความสามารถโดยธรรมชาติในการสรุปเป็นภาษาอื่น แต่เราเน้นย้ำอย่างชัดเจนถึงการรวมภาษาอื่น ๆ อีก 27 ภาษาไว้ในการฝึกอบรมของเรา:
ภาษาประจำภูมิภาค ยุโรปตะวันตก เยอรมัน ฝรั่งเศส สเปน โปรตุเกส อิตาลี ดัตช์ ยุโรปตะวันออกและยุโรปกลาง รัสเซีย เช็ก โปแลนด์ ตะวันออกกลาง อารบิก เปอร์เซีย ฮิบรู ตุรกี เอเชียตะวันออก ญี่ปุ่น เกาหลี เอเชียตะวันออกเฉียงใต้ เวียดนาม ไทย อินโดนีเซีย มาเลย์ ลาว, พม่า, เซบู, เขมร, ตากาล็อก, ฮินดีเอเชียใต้, เบงกาลี, อูรดูนอกจากนี้ เรายังใช้ความพยายามอย่างมากในการแก้ไขปัญหาการแปลงรหัสที่มักเกิดขึ้นในการประเมินหลายภาษา ดังนั้น ความสามารถของแบบจำลองของเราในการจัดการกับปรากฏการณ์นี้จึงได้รับการปรับปรุงอย่างมาก การประเมินโดยใช้ตัวชี้นำที่มักล้วงเอาการสลับรหัสข้ามภาษามายืนยันการลดลงอย่างมีนัยสำคัญในปัญหาที่เกี่ยวข้อง
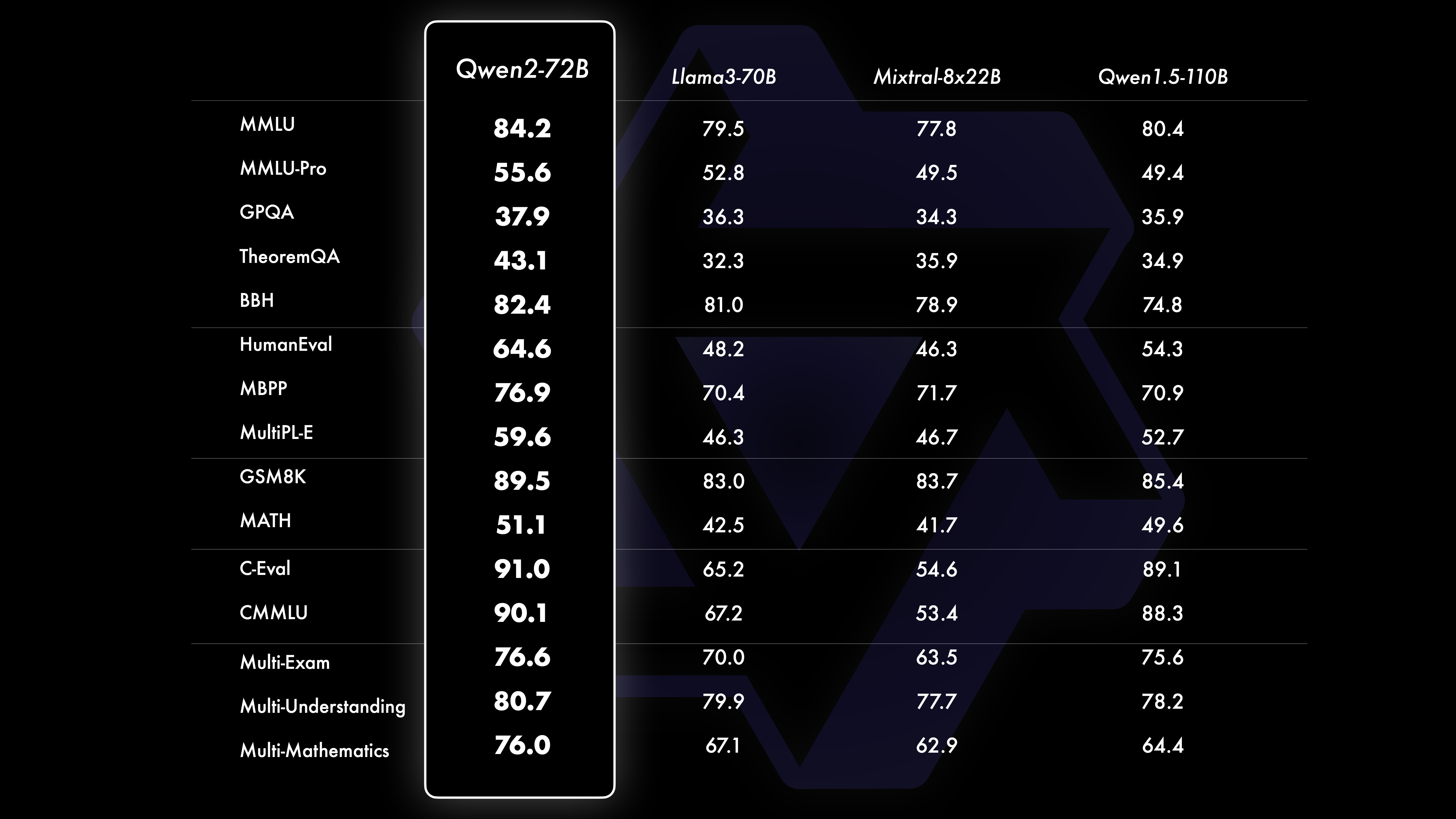
ผลงานผลการทดสอบเปรียบเทียบแสดงให้เห็นว่าประสิทธิภาพของโมเดลขนาดใหญ่ (พารามิเตอร์ 70B+) ได้รับการปรับปรุงอย่างมีนัยสำคัญเมื่อเทียบกับ Qwen1.5 การทดสอบนี้มีศูนย์กลางอยู่ที่โมเดลขนาดใหญ่ Qwen2-72B ในแง่ของโมเดลภาษาพื้นฐาน เราได้เปรียบเทียบประสิทธิภาพของ Qwen2-72B กับโมเดลแบบเปิดที่ดีที่สุดในปัจจุบัน ในแง่ของความเข้าใจภาษาธรรมชาติ การได้มาซึ่งความรู้ ความสามารถในการเขียนโปรแกรม ความสามารถทางคณิตศาสตร์ ความสามารถหลายภาษา และความสามารถอื่นๆ ด้วยชุดข้อมูลที่คัดสรรมาอย่างดีและวิธีการฝึกอบรมที่ได้รับการปรับปรุง ทำให้ Qwen2-72B มีประสิทธิภาพเหนือกว่ารุ่นชั้นนำ เช่น Llama-3-70B และยังมีประสิทธิภาพเหนือกว่า Qwen1.5- รุ่นก่อนหน้าด้วยพารามิเตอร์จำนวนน้อยกว่า
หลังจากการฝึกอบรมล่วงหน้าขนาดใหญ่อย่างกว้างขวาง เราจะทำการฝึกอบรมหลังการฝึกอบรมเพื่อเพิ่มความฉลาดของ Qwen และทำให้มันใกล้ชิดกับมนุษย์มากขึ้น กระบวนการนี้ช่วยปรับปรุงความสามารถของโมเดลในด้านต่างๆ เช่น การเขียนโค้ด คณิตศาสตร์ การใช้เหตุผล การปฏิบัติตามคำสั่ง และความเข้าใจหลายภาษา นอกจากนี้ ยังปรับเอาต์พุตของโมเดลให้สอดคล้องกับคุณค่าของมนุษย์ เพื่อให้มั่นใจว่ามีประโยชน์ ซื่อสัตย์ และไม่เป็นอันตราย ขั้นตอนหลังการฝึกอบรมของเราได้รับการออกแบบโดยมีหลักการของการฝึกอบรมที่ปรับขนาดได้และมีคำอธิบายประกอบโดยมนุษย์น้อยที่สุด โดยเฉพาะอย่างยิ่ง เราศึกษาวิธีการรับข้อมูลการนำเสนอและข้อมูลความชอบคุณภาพสูง เชื่อถือได้ หลากหลายและสร้างสรรค์ผ่านกลยุทธ์การจัดตำแหน่งอัตโนมัติต่างๆ เช่น การสุ่มตัวอย่างการปฏิเสธสำหรับคณิตศาสตร์ ผลตอบรับการดำเนินการสำหรับการเขียนโค้ดและการติดตามคำแนะนำ และการแปลกลับสำหรับการเขียนเชิงสร้างสรรค์ , การกำกับดูแลการแสดงบทบาทสมมติที่ปรับขนาดได้ และอื่นๆ สำหรับการฝึกอบรม เราใช้การผสมผสานระหว่างการปรับแต่งแบบละเอียดภายใต้การดูแล การฝึกอบรมโมเดลการให้รางวัล และการฝึกอบรม DPO ออนไลน์ นอกจากนี้เรายังใช้เครื่องมือเพิ่มประสิทธิภาพการผสานออนไลน์แบบใหม่เพื่อลดภาษีการจัดตำแหน่ง ความพยายามร่วมกันเหล่านี้ช่วยปรับปรุงความสามารถและความชาญฉลาดของโมเดลของเราอย่างมาก ดังที่แสดงในตารางด้านล่าง
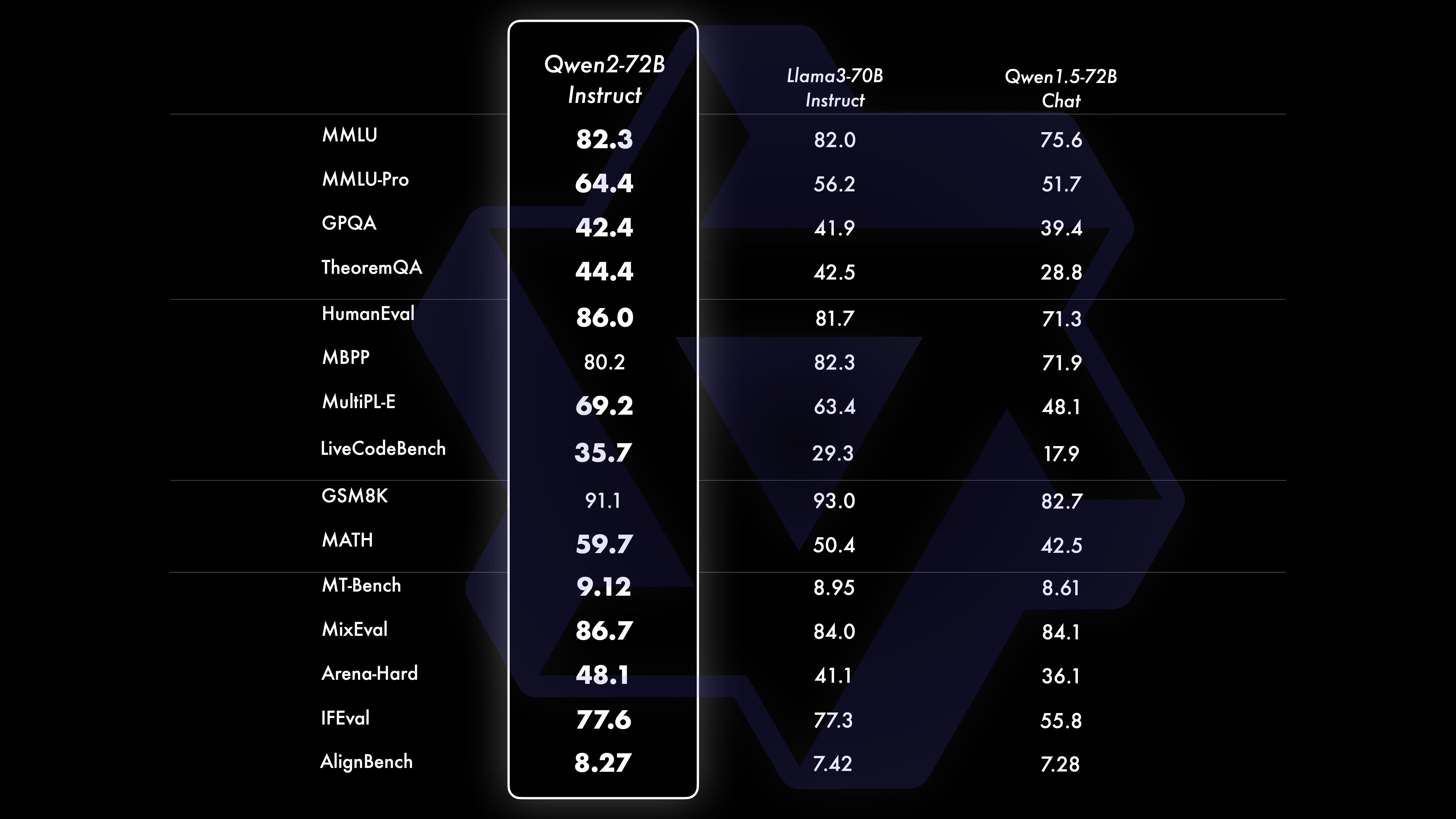
เราทำการประเมิน Qwen2-72B-Instruct อย่างครอบคลุม โดยครอบคลุมการวัดประสิทธิภาพ 16 รายการในสาขาต่างๆ Qwen2-72B-Instruct สร้างความสมดุลระหว่างการได้รับความสามารถที่ดีขึ้นและความสอดคล้องกับคุณค่าของมนุษย์ โดยเฉพาะอย่างยิ่ง Qwen2-72B-Instruct มีประสิทธิภาพเหนือกว่า Qwen1.5-72B-Chat อย่างมากในทุกการวัดประสิทธิภาพ และยังให้ประสิทธิภาพที่แข่งขันได้เมื่อเทียบกับ Llama-3-70B-Instruct
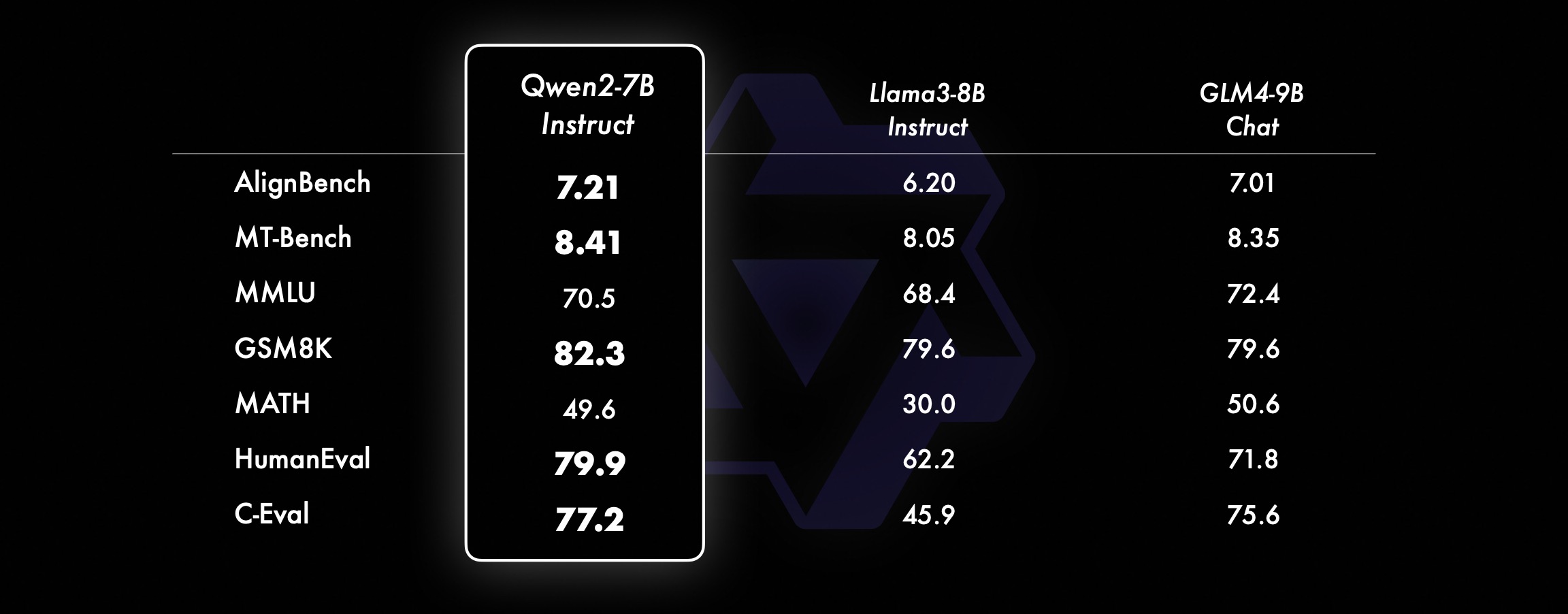
ในรุ่นขนาดเล็ก รุ่น Qwen2 ของเรายังมีประสิทธิภาพเหนือกว่ารุ่น SOTA ที่คล้ายกันและใหญ่กว่าอีกด้วย เมื่อเทียบกับรุ่น SOTA ที่เพิ่งเปิดตัว Qwen2-7B-Instruct ยังคงแสดงให้เห็นถึงข้อได้เปรียบในการทดสอบเกณฑ์มาตรฐานต่างๆ โดยเฉพาะอย่างยิ่งในการเข้ารหัสและตัวบ่งชี้ที่เกี่ยวข้องกับภาษาจีน
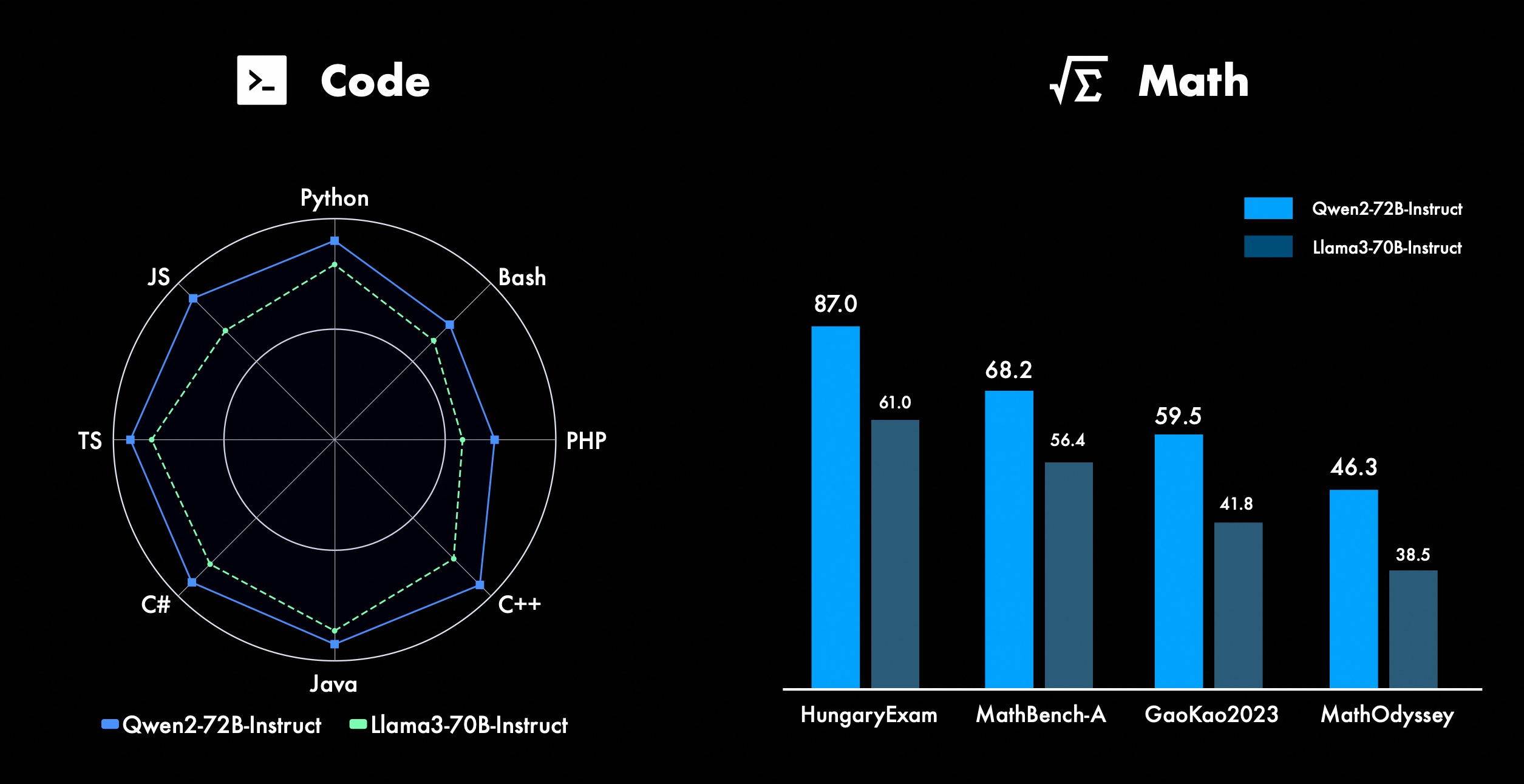
เรากำลังปรับปรุงฟีเจอร์ขั้นสูงของ Qwen อย่างต่อเนื่อง โดยเฉพาะในด้านการเขียนโค้ดและคณิตศาสตร์ ในส่วนของการเขียนโค้ด เราได้บูรณาการประสบการณ์การฝึกเขียนโค้ดและข้อมูลของ CodeQwen1.5 ได้สำเร็จ ส่งผลให้ Qwen2-72B-Instruct ได้รับการปรับปรุงที่สำคัญในภาษาการเขียนโปรแกรมต่างๆ ในทางคณิตศาสตร์ Qwen2-72B-Instruct แสดงให้เห็นถึงความสามารถที่เพิ่มขึ้นในการแก้ปัญหาทางคณิตศาสตร์โดยใช้ประโยชน์จากชุดข้อมูลที่กว้างขวางและมีคุณภาพสูง
ใน Qwen2 โมเดลการปรับคำสั่งทั้งหมดได้รับการฝึกฝนเกี่ยวกับบริบทความยาว 32k และคาดการณ์ความยาวบริบทที่ยาวขึ้นโดยใช้เทคนิค เช่น YARN หรือ Dual Chunk Attention
ภาพด้านล่างแสดงผลการทดสอบของเราเกี่ยวกับ Needle ในกองหญ้า เป็นที่น่าสังเกตว่า Qwen2-72B-Instruct สามารถจัดการงานการแยกข้อมูลได้อย่างสมบูรณ์แบบในบริบท 128k เมื่อรวมกับประสิทธิภาพอันทรงพลังโดยธรรมชาติแล้ว สามารถใช้งานได้เมื่อทรัพยากรเพียงพอ . กรณีนี้จะกลายเป็นตัวเลือกแรกสำหรับการประมวลผลงานข้อความยาว
นอกจากนี้ ยังเป็นที่น่าสังเกตว่าความสามารถที่น่าประทับใจของรุ่นอื่นๆ ในซีรีส์นี้: Qwen2-7B-Instruct จัดการบริบทได้มากถึง 128k เกือบจะสมบูรณ์แบบ Qwen2-57B-A14B-Instruct จัดการบริบทได้มากถึง 64k และซีรีส์ The two โมเดลขนาดเล็กรองรับบริบท 32k
นอกเหนือจากโมเดลบริบทแบบยาวแล้ว เรายังเปิดซอร์สโซลูชันพร็อกซีเพื่อการประมวลผลเอกสารที่มีแท็กมากถึง 1 ล้านแท็กอย่างมีประสิทธิภาพ สำหรับรายละเอียดเพิ่มเติม โปรดดูโพสต์บนบล็อกเฉพาะของเราในหัวข้อนี้
ตารางด้านล่างแสดงสัดส่วนของคำตอบที่เป็นอันตรายซึ่งสร้างขึ้นโดยแบบจำลองขนาดใหญ่สำหรับข้อความค้นหาที่ไม่ปลอดภัยในหลายภาษาสี่หมวดหมู่ (กิจกรรมที่ผิดกฎหมาย การฉ้อโกง ภาพอนาจาร ความรุนแรงส่วนตัว) ข้อมูลการทดสอบมาจาก Jailbreak และแปลเป็นหลายภาษาเพื่อการประเมินผล เราพบว่า Llama-3 ไม่สามารถจัดการสัญญาณหลายภาษาได้อย่างมีประสิทธิภาพ ดังนั้นจึงไม่ได้รวมไว้ในการเปรียบเทียบ จากการทดสอบนัยสำคัญ (P_value) เราพบว่าประสิทธิภาพการรักษาความปลอดภัยของโมเดล Qwen2-72B-Instruct เทียบเท่ากับ GPT-4 และดีกว่ารุ่น Mistral-8x22B อย่างมาก
ภาษา กิจกรรมที่ผิดกฎหมาย การฉ้อโกง ภาพอนาจาร ความเป็นส่วนตัว ความรุนแรง GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinese0%13 %0%0%17%0%43%47%53%0%10%0%ภาษาอังกฤษ0%7%0%0%23% 0%37%67%63%0%27%3%บัญชีลูกหนี้0%13% 0%0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%ฝรั่งเศส0%3% 0%3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%จุด0%7%0% 3%7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0% 4%11%0%22%26%22%0%0%0%เฉลี่ย0%8%0% 3%11%2%27%39%31%3%16%2% ใช้ Qwen2 เพื่อการพัฒนาขณะนี้โมเดลทั้งหมดได้รับการเผยแพร่แล้วใน Hugging Face และ ModelScope คุณสามารถเยี่ยมชมการ์ดโมเดลเพื่อดูวิธีการใช้งานโดยละเอียด และเรียนรู้เพิ่มเติมเกี่ยวกับคุณลักษณะ ประสิทธิภาพ และข้อมูลอื่น ๆ ของแต่ละรุ่น
เป็นเวลานานแล้วที่เพื่อนหลายคนสนับสนุนการพัฒนาของ Qwen รวมถึงการปรับแต่งอย่างละเอียด (Axolotl, Llama-Factory, Firefly, Swift, Xtuner), การหาปริมาณ (AutoGPTQ, AutoAWQ, Neural Compressor), การใช้งาน (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), แพลตฟอร์ม API (ร่วมกัน, ดอกไม้ไฟ, OpenRouter), Local Run (MLX, Llama.cpp, Ollama, LM Studio), Agent และ RAG Framework (LlamaIndex, CrewAI, OpenDevin), การประเมิน (LMSys, OpenCompass, Open LLM Leaderboard), การฝึกโมเดล (Dolphin, Openbuddy) ฯลฯ เกี่ยวกับวิธีใช้ Qwen2 กับเฟรมเวิร์กของบุคคลที่สาม โปรดดูเอกสารประกอบที่เกี่ยวข้องตลอดจนเอกสารอย่างเป็นทางการของเรา

มีทีมและบุคคลมากมายที่มีส่วนร่วมใน Qwen โดยที่เราไม่ได้กล่าวถึง เราขอขอบคุณการสนับสนุนของพวกเขาอย่างจริงใจ และหวังว่าความร่วมมือของเราจะส่งเสริมการวิจัยและพัฒนาในชุมชน AI แบบโอเพ่นซอร์ส
ใบอนุญาตครั้งนี้เราเปลี่ยนการอนุญาตของโมเดลเป็นสิทธิ์อื่น Qwen2-72B และโมเดลการปรับแต่งคำสั่งยังคงใช้สิทธิ์ใช้งาน Qianwen ดั้งเดิม ในขณะที่รุ่นอื่นๆ ทั้งหมด รวมถึง Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B และ Qwen2-57B-A14B ได้เปลี่ยนไปใช้ Apache2.0 !เราเชื่อว่า การเปิดตัวโมเดลของเราสู่ชุมชนเพิ่มเติมสามารถเร่งการใช้งานและการจำหน่าย Qwen2 ทั่วโลกได้
อะไรต่อไปสำหรับ Qwen2?เรากำลังฝึกอบรมโมเดล Qwen2 ที่ใหญ่ขึ้นเพื่อสำรวจส่วนขยายโมเดลเพิ่มเติมตลอดจนส่วนขยายข้อมูลล่าสุดของเรา นอกจากนี้ เรายังขยายโมเดลภาษา Qwen2 ให้เป็นแบบหลายรูปแบบ ซึ่งสามารถเข้าใจข้อมูลภาพและเสียงได้ ในอนาคตอันใกล้นี้ เราจะยังคงเปิดตัวโมเดลโอเพ่นซอร์สใหม่ๆ ต่อไปเพื่อเร่ง AI แบบโอเพ่นซอร์ส คอยติดตาม!
อ้างเราจะเผยแพร่รายงานทางเทคนิคเกี่ยวกับ Qwen2 เร็วๆ นี้ คำคมยินดีต้อนรับ!
@article{qwen2 การประเมินโมเดลภาษาพื้นฐานภาคผนวกการประเมินแบบจำลองพื้นฐานมุ่งเน้นไปที่ประสิทธิภาพของแบบจำลองเป็นหลัก เช่น ความเข้าใจภาษาธรรมชาติ การตอบคำถามทั่วไป การเขียนโค้ด คณิตศาสตร์ ความรู้ทางวิทยาศาสตร์ การใช้เหตุผล และความสามารถหลายภาษา
ชุดข้อมูลที่ประเมินได้แก่:
งานภาษาอังกฤษ: MMLU (5 ครั้ง), MMLU-Pro (5 ครั้ง), GPQA (5 ครั้ง), ทฤษฎีบท QA (5 ครั้ง), BBH (3 ครั้ง), HellaSwag (10 ครั้ง), Winogrande (5 ครั้ง), TruthfulQA ( 0 ครั้ง), ARC-C (25 ครั้ง)
งานเขียนโค้ด: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
งานคณิตศาสตร์: GSM8K (4 ครั้ง), MATH (4 ครั้ง)
งานภาษาจีน: C-Eval (5 นัด), CMMLU (5 นัด)
งานหลายภาษา: การสอบหลายรายการ (M3Exam 5 ครั้ง, IndoMMLU 3 ครั้ง, ruMMLU 5 ครั้ง, mmMLU 5 ครั้ง), ข้อสอบหลายข้อ (BELEBELE 5 ครั้ง, XCOPA 5 ครั้ง, XWinograd 5 ครั้ง, XStoryCloze 0 ครั้ง, PAWS-X 5 ครั้ง) , คณิตศาสตร์หลายรายการ (MGSM 8 ครั้ง), การแปลหลายรายการ (Flores-1,015 ครั้ง)
ชุดข้อมูลประสิทธิภาพ Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureDenseDenseDenseDense#Activated Parameters 21B39B70B72B110B72B#Parameters 236B140B70B72B1 10B72B ภาษาอังกฤษ Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552 845.849.455.6การประกันคุณภาพ-34.336.336.335.937.9ทฤษฎีบทถาม-ตอบ-35.932.329.334.943.1ไป่บีเฮย 78.978.981.065.574.88 2.4 ชิรัสวัก 87.888.788.086 587.6 Windows ขนาดใหญ่ 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 ถามตอบอย่างตรงไปตรงมา 42.251.045.659.649.654.8 การประเมินกำลังคนด้านการเข้ารหัส 45.746.348.246.354.364.6 กรมบริการสาธารณะของมาเลเซีย 73 .971.770.466.970.976.9 การประเมิน 55.054.154.852.957 .765.4 ต่างๆ 44.446.746.341.852.759.6 คณิตศาสตร์ GSM8K79 283.783.079.585.489.5 คณิตศาสตร์ 43.641.742.534.149.651.1 การประเมิน C ภาษาจีน 81.754.665. 284.189.191.0 University of Montreal, แคนาดา 84.053 .467.283.588.390.1 หลายภาษาและการสอบหลายภาษา 67 .563.570.066.475.676.6ความเข้าใจหลายประการ 77.077.779.978.278.280.7คณิตศาสตร์หลายรายการ 58.862.967.161.764.476.0การแปลหลายรายการ 36.023.338.035.636.2 37.8Qwen2-57B-A14B ชุดข้อมูล Jabba Mixtral-8x7B Instrument-1.5-34BQwen1 .5-32BQwen2-57B-A14B สถาปัตยกรรม MoE MoE หนาแน่น หนาแน่น MoE #พารามิเตอร์ที่เปิดใช้งาน 12B12B34B32B14B #พารามิเตอร์ 52B47B34B32B57B ภาษาอังกฤษ Moleman Lu 67.471.877.174.376.5MMLU - Professional Edition - 41.048.344.043.0 การประกันคุณภาพ - 29.2 - 30.834.3 ทฤษฎีบทคำถามและคำตอบ - 23 2 - 28.833.5 ไป่เป่ย ดำ 45.450.376.466.867.0 ชีเอลา Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 คำถามและคำตอบที่ตรงไปตรงมา 46.451.153.957.457.7 การประเมินกำลังคนในการเข้ารหัส 29.337.246.343 353.0 การบริการสาธารณะ มาเลเซีย - 63.965.564.271.9 การประเมิน - 46.451 .950.457.2 หลากหลาย - 39.03 9.538.549 .8 คณิตศาสตร์ GSM8K59.962.582.776.880.7 คณิตศาสตร์-30.841.736.143.0 การประเมิน C ภาษาจีน---83.587.7 University of Montreal, แคนาดา--84.882.388.5 หลายภาษา และการสอบหลายรายการ-56.158.361.665.5 ความเข้าใจหลายฝ่าย -70.773.976.577.0คณิตศาสตร์หลายรายการ -45.049.356.162.3การแปลหลายรายการ -29.830.033.534.5Qwen2-7B ชุดข้อมูล Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# พารามิเตอร์ 7.2B850 ล้าน 8.0B7.7B7.6B# พารามิเตอร์ที่ไม่ใช่ emb 7.0B780 ล้าน 7.0B650 ล้าน 650 ล้านภาษาอังกฤษ Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 การประกันคุณภาพ 24.72 5 .725.826. 731.8 ทฤษฎีบท Q&A 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 354.260.6คำถามและคำตอบที่ตรงไปตรงมา 42.244 .844.051.154.2 การประเมินกำลังคนในการเขียนโค้ด 29.337.233.536 .051.2 การบริการสาธารณะมาเลเซีย 51.150.653.951.665.9 การประเมิน 36.439.640.340.054.2 พหุคูณ 29.429.722.628.146.3 คณิตศาสตร์ GSM8K52.246.456.0 62.579.9 คณิตศาสตร์ 13.124.320.5 20.344.2 การประเมิน C ของมนุษย์ของจีน 47.443.649.574.183.2 มหาวิทยาลัยมอนทรีออล , แคนาดา -- 50.873.183.9 การสอบพหุภาษา 47.142.752.347.759.2 ความเข้าใจพหุคูณ 63.358.368.667.672.0 คณิตศาสตร์หลายตัวแปร 26.339.136.337.357.5 การแปลพหุคูณ 23.331.231 .928.431.5Qwen ชุดข้อมูล 2 -0.5B และ Qwen2-1.5B Phi-2Gemma -2B CPM ขั้นต่ำ Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# พารามิเตอร์ที่ไม่ใช่ Emb 250 ล้าน 2.0B2.4B1.3B035 ล้าน 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional Edition-15.9--14.721.8 ทฤษฎีบทถามตอบ----8.915.0 การประเมินกำลังคน 47.622.050.020.122.031.1 กรมบริการสาธารณะของมาเลเซีย 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 คณิตศาสตร์ 3.511.810.210 110.721.7 ไป่บี สีดำ 43.435.236.924.228.437 .2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 ถามตอบอย่างตรงไปตรงมา 44.533.1-39.439.745.9C - การประเมิน 23.428.05 1.159.758.270.6 มหาวิทยาลัยมอนทรีออล , แคนาดา 24.2 - 51.157.855.170.3 การประเมินโมเดลการปรับแต่งคำสั่ง Qwen2-72B - ชุดข้อมูลคำแนะนำ Camel - 3-70B - Guidance Qwen1.5-72B - Chat Qwen2-72B - Guidance English Mohr Man Lu 82.075.682.3MMLU - Professional Edition 56.251 .764.4 การประกันคุณภาพ 41.939.442.4 ทฤษฎีบท Q&A 42.528.844.4MT - Bench8.958.619.12 Arena - Hard 41.136.148.1 IFEval (การเข้าถึงอย่างเข้มงวดทันที) 77.355.877.6 การประเมินกำลังคนการเข้ารหัส 81.771.386.0 บริการสาธารณะ 82.371.980.2 หลายรายการ 63.448.169.2 การประเมิน 75.266.979.0 การทดสอบโค้ดสด 29.317.935.7 คณิตศาสตร์ GSM 8K93.082.7 91. 1 คณิตศาสตร์ 50.442.559.7 การประเมิน C ภาษาจีน 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-ข้อมูลคำสั่ง setMixtral-8x7B-คำสั่ง-v0.1Yi- 1.5-34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - สถาปัตยกรรมแนะแนวกระทรวงศึกษาธิการ หนาแน่น กระทรวงศึกษาธิการ #เปิดใช้งานพารามิเตอร์ 12B34B32B14B #Parameter 47B34B32B57B อังกฤษ Mohr Man Lu 71.476.874.875.4MMLU - Professional Edition 43.352.346 .452.8 การประกันคุณภาพ -- 30.834.3 คำถามและคำตอบทางทฤษฎี - -30.933.1MT-Bench8.308.508.308.55 การประเมินกำลังคนในการเข้ารหัส 45.175.268.379.9 บริการสาธารณะของมาเลเซีย 59.574.667.970.9 ต่างๆ --50.766.4 การประเมิน 48.5-63.671 6 การทดสอบรหัสสด 12.3-15.225.5 คณิตศาสตร์ GSM8K65.790.283.679.6 คณิตศาสตร์ 30.750.142.449.1 การประเมิน C จีน--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide ชุดข้อมูล Camel-3-8B-Guide Yi-1.5- 9B-Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide อังกฤษ Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 การประกันคุณภาพ 34.2--27.825.3 ทฤษฎีบท Q&A 23.0 --14.125 .3MT-Bench8.058.208.357.608.41 การเข้ารหัสด้านมนุษยธรรม 62.266.571.846.379.9 บริการสาธารณะมาเลเซีย 67.9--48.967.2 หลายรายการ 48.5--27.259.1 การประเมิน 60.9--44.870.3 การทดสอบโค้ดสด 17.3-- 6.026 .6 คณิตศาสตร์ GSM8K79.684.879.660.382.3 คณิตศาสตร์ 30.047.750.623.249.6 การประเมิน C ภาษาจีน 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 ชุดข้อมูล Qwen2-0.5B-Instruct และ Qwen2-1.5B-Instruct คิวเวน1.5 -0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 การประเมินกำลังคน 9.117.125.037.8GSM8K11.340.135.361.6C-การประเมิน 37.245.255.3 63.8IFEval (พร้อมท์ให้เข้าถึงอย่างเข้มงวด) คำสั่ง 14.620.016.829.0 ปรับความสามารถหลายภาษาของโมเดลเราเปรียบเทียบโมเดลการปรับแต่งคำสั่ง Qwen2 กับ LLM ล่าสุดอื่นๆ บนเกณฑ์มาตรฐานแบบเปิดข้ามภาษา รวมถึงการประเมินโดยมนุษย์ สำหรับข้อมูลพื้นฐาน เราจะนำเสนอผลลัพธ์บนชุดข้อมูลการประเมิน 2 ชุด:
M-MMLU ของ Okapi: การประเมินความรู้ทั่วไปหลายภาษา (เราใช้ชุดย่อยของ ar, de, es, fr, it, nl, ru, uk, vi, zh สำหรับการประเมิน) MGSM: สำหรับการประเมินภาษาเยอรมัน อังกฤษ สเปน ฝรั่งเศส และคณิตศาสตร์ใน ภาษาญี่ปุ่น รัสเซีย ไทย จีน และบราซิลผลลัพธ์จะถูกเฉลี่ยในภาษาต่างๆ สำหรับแต่ละเกณฑ์มาตรฐานและมีดังต่อไปนี้:
ตัวอย่าง M-MMLU (5 นัด) MGSM (0 นัด, CoT) LLM ที่เป็นกรรมสิทธิ์ GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 โอเพ่นซอร์ส LL.M command-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -ไกด์ 60.057.0Qwen2-57B-A14B-ไกด์ 68.074.0Qwen2-72B-ไกด์ 78.086.6สำหรับการประเมินด้วยตนเอง เราจะเปรียบเทียบ Qwen2-72B-Instruct กับ GPT3.5, GPT4 และ Claude-3-Opus โดยใช้ชุดการประเมินภายในองค์กร ซึ่งประกอบด้วย 10 ภาษา ar, es, fr, ko, th, vi, pt, id , ja และ ru (ช่วงคะแนนตั้งแต่ 1 ถึง 5):
โมเดลบัญชีลูกหนี้ Spanish French Corri Six Points ID Jiaru Average Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 724.324.09 GPT-4-เทอร์โบ- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-ไกด์ 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 .943.873.833.953.553.773.063.633.71GPT- 3.5-เทอร์โบ-11062.524. 073.472.373.382.903.373.562.753.243.16จัดกลุ่มตามประเภทงาน ผลลัพธ์มีดังนี้
แบบจำลองความรู้ความเข้าใจในการสร้างคณิตศาสตร์ Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61 GPT-4-06133.424. 32GPT-3.5-เทอร์โบ-11063.373.673.892.97ผลลัพธ์เหล่านี้แสดงให้เห็นถึงความสามารถหลายภาษาอันทรงพลังของโมเดลการปรับแต่งคำสั่ง Qwen2
โมเดลซีรีส์โอเพ่นซอร์ส Qwen2 ของอาลีบาบาได้รับการปรับปรุงประสิทธิภาพและความสามารถหลายภาษาอย่างมีนัยสำคัญ ซึ่งมีส่วนสำคัญต่อชุมชน AI โอเพ่นซอร์ส ในอนาคต Qwen2 จะยังคงพัฒนาและขยายขนาดโมเดลและความสามารถหลายรูปแบบต่อไป ซึ่งคุ้มค่ากับการรอคอย