隨著AI技術快速發展,視覺語言模型的需求日益增長,但其高昂的運算資源需求限制了其在一般設備上的應用。 Downcodes小編今天要為大家介紹一款名為SmolVLM的輕量級視覺語言模型,它能夠在資源有限的裝置上高效運行,例如筆記型電腦和消費級GPU。 SmolVLM的出現,為更多用戶帶來了體驗先進AI技術的機會,降低了使用門檻,同時也為開發者提供了更便利的研究工具。
近年來,機器學習模型在視覺和語言任務方面的應用需求日益增長,但大多數模型都需要龐大的運算資源,無法在個人裝置上有效運作。尤其是像筆記型電腦、消費級GPU 和行動裝置等小型設備,在處理視覺語言任務時面臨巨大的挑戰。
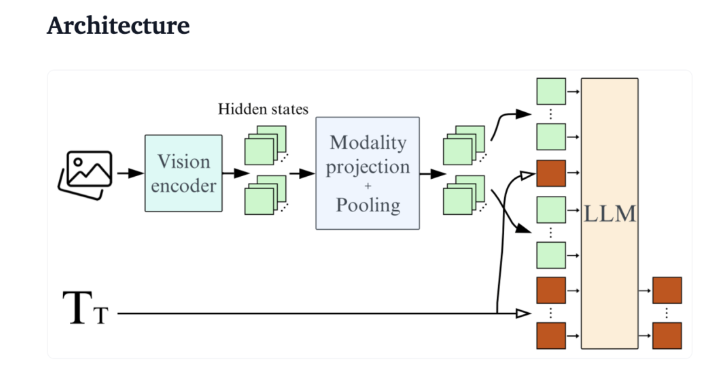
以Qwen2-VL 為例,雖然其性能卓越,但對硬體的要求較高,限制了其在即時應用中的可用性。因此,開發出輕量化模型以便於在較低資源下運行,成為了重要需求。
Hugging Face 近期發表了SmolVLM,這是一款專為裝置端推理設計的2B 參數視覺語言模型。 SmolVLM 在GPU 記憶體使用和令牌產生速度方面的表現超越了其他同類模型。其主要特性是能夠在較小的裝置上有效運行,例如筆記型電腦或消費級GPU,而不會犧牲效能。 SmolVLM 在性能和效率之間找到了一個理想的平衡,解決了以往同類模型難以克服的問題。
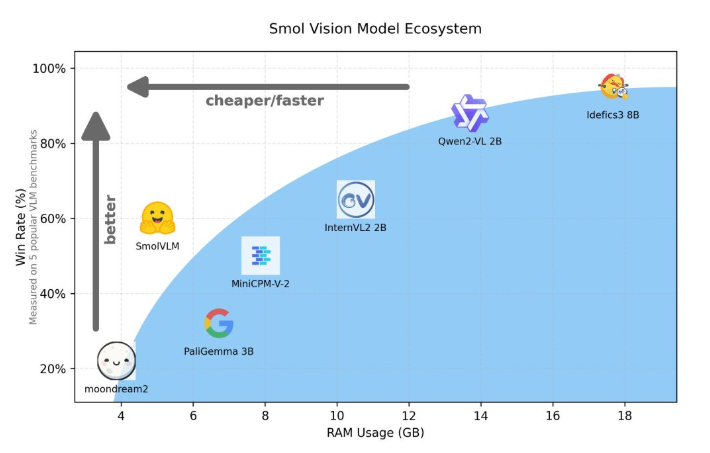
與Qwen2-VL2B 相比,SmolVLM 生成代幣的速度快了7.5到16倍,歸功於其優化的架構,使得輕量級推理成為可能。這項效率不僅為最終用戶帶來了實用的好處,也大大提升了使用體驗。
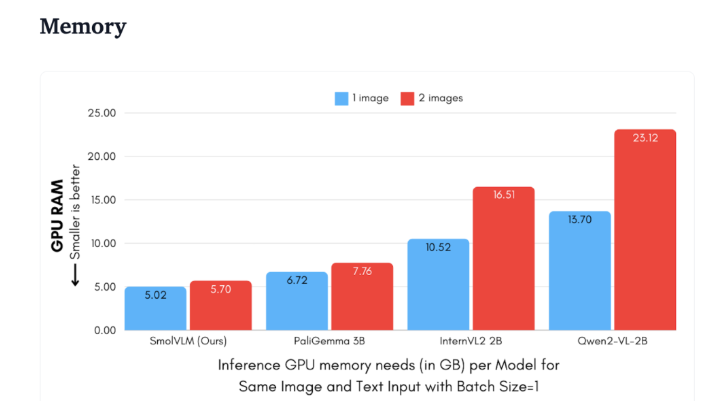
從技術角度來看,SmolVLM 具有最佳化的架構,支援高效的設備端推理。使用者甚至可以在Google Colab 上輕鬆進行微調,大大降低了試驗和開發的門檻。
由於記憶體佔用小,SmolVLM 能夠在先前無法承載同類模型的裝置上順利運作。在對50幀YouTube 影片進行測試時,SmolVLM 表現出色,得分達到27.14%,並在資源消耗上優於兩款更為消耗資源的模型,顯示了其強大的適應能力和靈活性。
SmolVLM 在視覺語言模型領域具有重要的里程碑意義。它的推出使得複雜的視覺語言任務能夠在日常設備上運行,填補了當前AI 工具中的一項重要空白。
SmolVLM 不僅在速度和效率方面表現優異,還為開發者和研究者提供了一個強大的工具,以便於進行視覺語言處理,而無需投入高昂的硬體費用。隨著AI 技術的不斷普及,像SmolVLM 這樣的模型將使得強大的機器學習能力變得更加觸手可及。
demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
總而言之,SmolVLM 為輕量級視覺語言模型樹立了新的標桿,它高效的性能和便捷的使用方式,將極大地推動AI技術的普及和發展。 期待未來有更多類似的創新,讓AI技術惠及更多人。