近年來,大型語言模型的訓練成本居高不下,成為限制AI發展的重要因素。如何降低訓練成本,提高效率,成為業界的焦點。 Downcodes小編為您帶來一篇來自哈佛大學和史丹佛大學研究人員的最新論文解讀,該論文提出了一種「精度感知」縮放法則,透過調整模型訓練精度來有效降低訓練成本,甚至在某些情況下還能提升模型性能。讓我們一起深入了解這項令人振奮的研究成果。
在人工智慧領域,規模越大似乎意味著能力越強。為了追求更強大的語言模型,各大科技公司都在瘋狂堆疊模型參數和訓練數據,結果卻發現成本也跟著水漲船高。難道就沒有一種既經濟又高效的方法來訓練語言模型嗎?
來自哈佛大學和史丹佛大學的研究人員最近發表了一篇論文,他們發現,模型訓練的精確度(precision) 就像一把隱藏的鑰匙,可以解鎖語言模型訓練的「成本密碼」。
什麼是模型精確度?簡單來說,它指的是模型參數和計算過程中使用的數字位數。傳統的深度學習模型通常使用32位元浮點數(FP32)進行訓練,但近年來,隨著硬體的發展,使用更低精度的數字類型,例如16位元浮點數(FP16)或8位元整數(INT8)進行訓練已經成為可能。
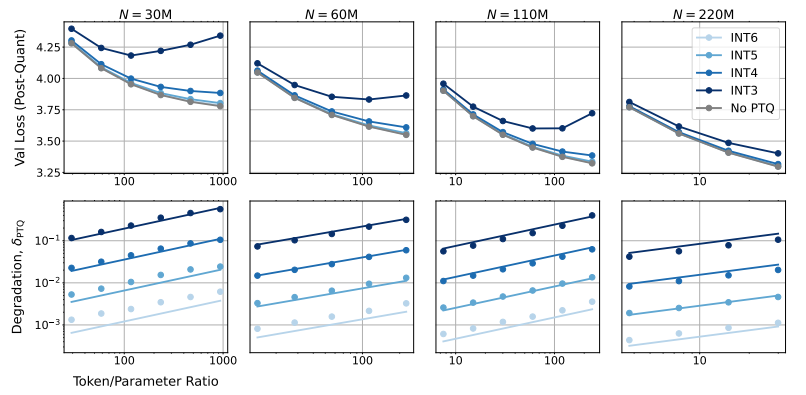
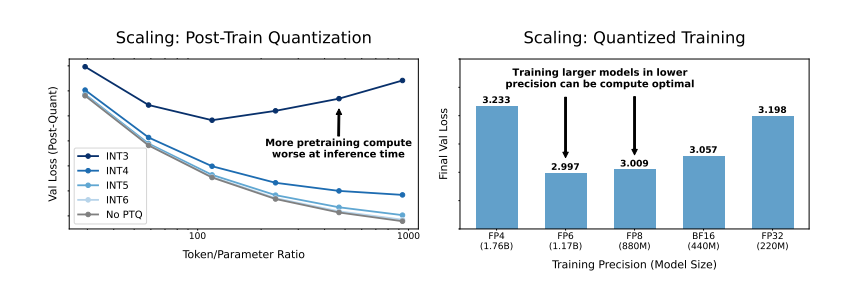
那麼,降低模型精確度會對模型效能產生什麼影響呢? 這正是這篇論文想要探究的問題。研究人員透過大量的實驗,分析了不同精度下模型訓練和推理的成本和性能變化,並提出了一套全新的「精度感知」縮放法則。
他們發現,使用更低精度進行訓練可以有效降低模型的“有效參數數量”,從而減少訓練所需的計算量。這意味著,在相同的運算預算下,我們可以訓練更大規模的模型,或者在相同規模下,使用更低的精度可以節省大量的運算資源。
更令人驚訝的是,研究人員還發現,在某些情況下,使用更低的精度進行訓練反而可以提高模型的性能! 例如,對於那些需要進行“量化後訓練”(post-training quantization)的模型,如果在訓練階段就使用較低的精度,模型對量化後的精度降低會更加穩健,從而在推理階段表現出更好的性能。
那麼,我們應該選擇哪一種精確度來訓練模型呢?研究人員透過分析他們的縮放法則,得出了一些有趣的結論:
傳統的16位元精度訓練可能並非最優選擇。 他們的研究表明,7-8位精度可能是更經濟高效的選擇。
一味追求超低精準度(例如4位)訓練也並非明智之舉。 因為在極低的精度下,模型的有效參數數量會急劇下降,為了維持性能,我們需要大幅增加模型規模,反而會導致更高的計算成本。
對於不同規模的模型,最佳訓練精度可能會有所不同。 對於那些需要進行大量「過度訓練」(overtraining)的模型,例如Llama-3和Gemma-2系列,使用更高的精度進行訓練反而可能更有經濟效率。
這項研究為我們理解和優化語言模型訓練提供了一個全新的視角。它告訴我們,精確度的選擇並非一成不變,而是需要根據具體的模型規模、訓練資料量和應用場景進行權衡。
當然,這項研究也存在一些限制。例如,他們使用的模型規模相對較小,實驗結果可能無法直接推廣到更大規模的模型。此外,他們只關注了模型的損失函數,並沒有對模型在下游任務上的表現進行評估。
儘管如此,這項研究仍具有重要的意義。它揭示了模型精度與模型性能和訓練成本之間的複雜關係,並為我們未來設計和訓練更強大、更經濟的語言模型提供了寶貴的insights。
論文:https://arxiv.org/pdf/2411.04330
總而言之,這項研究為降低大型語言模型訓練成本提供了新的想法和方法,為未來AI發展提供了重要的參考價值。 Downcodes小編期待更多關於模型精度研究的進展,為建構更經濟高效的AI模型貢獻力量。