Downcodes小編獲悉,非營利組織AI研究機構Ai2最近發布了其全新的OLMo2系列語言模型,這是其「開放語言模型」(OLMo)系列的第二代產品。 OLMo2秉持完全開放原始碼的概念,其訓練資料、工具和程式碼都完全公開,這在當今AI領域尤為重要,代表著開源AI發展的新高度。與其他聲稱「開放」的模型不同,OLMo2嚴格遵循開放原始碼倡議的定義,滿足了開源AI的嚴格標準,為AI社群提供了強大的技術支援和寶貴的學習資源。
非營利組織AI 研究機構Ai2最近發布了其於全新的OLMo2系列,這是該機構推出的「開放語言模型」(OLMo)系列的第二代模型。 OLMo2的發布不僅為AI社群提供了強大的技術支持,更以其完全開放原始碼的特性,代表了開源AI的最新發展。
與目前市場上其他「開放」語言模型如Meta的Llama系列不同,OLMo2符合開放原始碼倡議的嚴格定義,這意味著用於其開發的訓練資料、工具和程式碼都是公開的,任何人都可以訪問和使用。根據開放原始碼促進會的定義,OLMo2滿足了該機構對「開源AI」標準的要求,這項標準於今年10月最終確定。
Ai2在其部落格中提到,在OLMo2的開發過程中,所有的訓練資料、程式碼、訓練方案、評估方法以及中間檢查點都完全開放,旨在透過共享資源,推動開源社群的創新與發現。 「透過公開分享我們的數據、方案和發現,我們希望為開源社群提供發現新方法和創新技術的資源。」Ai2表示。
OLMo2系列包含兩個版本:一個是70億參數的OLMo7B,另一個是130億參數的OLMo13B。參數的數量直接影響模型的表現,參數較多的版本通常能處理較複雜的任務。在常見的文字任務中,OLMo2表現出色,能夠完成諸如回答問題、總結文件和編寫程式碼等任務。

圖源備註:圖片由AI生成,圖片授權服務商Midjourney
為訓練OLMo2,Ai2使用了包含五兆個token的資料集。 Token是語言模型中最小的單位,100萬個token大約等於75萬個單字。訓練資料包括來自高品質網站、學術論文、問答討論版以及合成數學練習冊的內容,這些資料經過精心篩選,以確保模型的高效性和準確性。
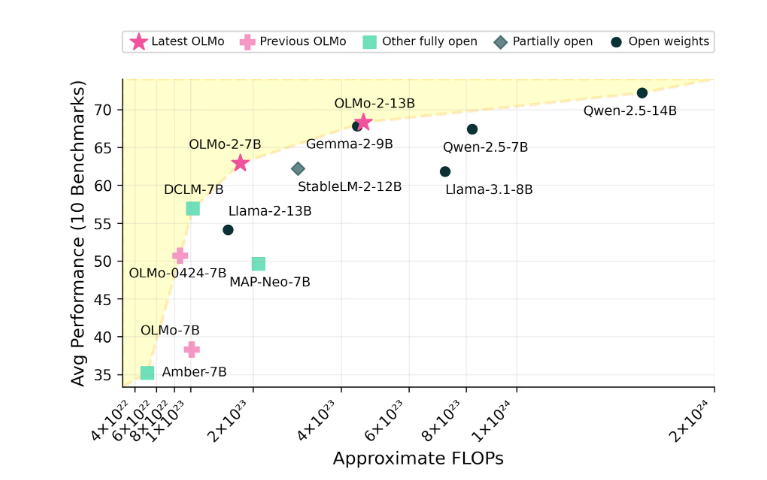
Ai2對OLMo2的表現充滿信心,聲稱在效能上已與Meta的Llama3.1等開源模型競爭。 Ai2指出,OLMo27B的表現甚至超越了Llama3.18B,成為目前最強的完全開放語言模型之一。所有OLMo2模型及其組件均可透過Ai2官網免費下載,並遵循Apache2.0許可,意味著這些模型不僅可以用於研究,也可以用於商業應用。
OLMo2的開源特性將大大促進AI領域的開放合作和創新,為研究人員和開發者提供更廣闊的發展空間。期待OLMo2在未來帶來更多突破和應用。