近年來,大型語言模型(LLM)在各個領域展現出驚人的能力,但其數學推理能力卻令人意外地薄弱。 Downcodes小編將為您解讀一項最新研究,該研究揭示了LLM在算術運算中令人匪夷所思的“秘訣”,並分析了這種方法的局限性及未來改進方向。這項研究不僅加深了我們對LLM內部運作機制的理解,也為提升LLM的數學能力提供了寶貴的參考。
最近,AI 大型語言模型(LLM)在各種任務中表現出色,寫詩、寫代碼、聊天都不在話下,簡直是無所不能!但是,你敢相信嗎?這些“天才”AI 居然是“數學菜鳥」!它們在處理簡單的算術題時經常翻車,讓人大跌眼鏡。
一項最新的研究揭開了LLM 算術推理能力背後的「奇葩」秘訣:它們既不依賴強大的演算法,也不完全依靠記憶,而是採用了一種被稱為「啟發式大雜燴」的策略!這就好比一個學生,沒有認真學習數學公式和定理,而是靠著一些「小聰明」和「經驗法則」來蒙答案。
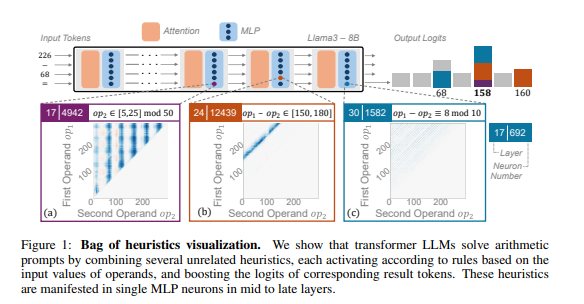
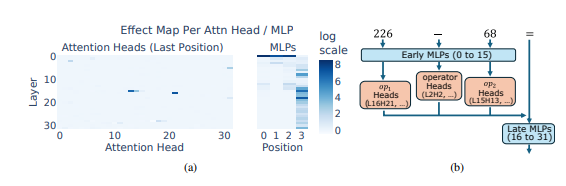
研究人員以算術推理作為典型任務,對Llama3、Pythia 和GPT-J 等多個LLM 進行了深入分析。他們發現,LLM 模型中負責算術計算的部分(稱為“電路”)是由許多單一神經元組成的,每個神經元都像一個“微型計算器”,只負責識別特定的數位模式並輸出對應的答案。 例如,一個神經元可能專門負責識別“個位數是8的數字”,另一個神經元則負責識別“結果在150到180之間的減法運算”。
這些「微型計算器」就像一堆雜亂無章的工具,LLM 並非按照特定的演算法來使用它們,而是根據輸入的數字模式,隨機地組合使用這些「工具」來計算答案。 這就像一個廚師,沒有固定的食譜,而是根據手邊現有的食材,隨意搭配,最終做出一道「黑暗料理」。
更令人驚訝的是,這種「啟發式大雜燴」的策略居然在LLM 訓練的早期就出現了,並且隨著訓練的進行逐漸完善。這意味著,LLM 從一開始就依賴這種「拼湊」式的推理方法,而不是在後期才發展出這種策略。
那麼,這種「奇葩」的算術推理方法會導致什麼問題呢?研究人員發現,「啟發式大雜燴」策略的泛化能力有限,容易出現錯誤。 這是因為LLM 所掌握的「小聰明」數量有限,而且這些「小聰明」本身也可能有缺陷,導致它們在遇到新的數字模式時無法給出正確答案。 就像一個只會做“番茄炒蛋”的廚師,突然讓他做一道“魚香肉絲”,他肯定會手忙腳亂,不知所措。
這項研究揭示了LLM 算術推理能力的局限性,也為未來改進LLM 的數學能力指明了方向。 研究人員認為,僅依靠現有的訓練方法和模型架構可能不足以提升LLM 的算術推理能力,需要探索新的方法來幫助LLM 學習更強大、更泛化的演算法,讓它們真正成為“數學高手” 。
論文網址:https://arxiv.org/pdf/2410.21272
總而言之,這項研究深入剖析了LLM在數學推理上的「奇葩」策略,為我們理解LLM的限制提供了新的視角,也為未來研究指明了方向。相信隨著技術的不斷發展,LLM的數學能力將會顯著提升。