Meta AI 震撼發布了名為SPIRIT LM 的基礎多模態語言模型,這是一個能夠自由混合文字和語音的里程碑式成果!它基於70 億參數的預訓練文字語言模型,透過持續訓練擴展到語音模態,實現了文字和語音的雙模態理解與生成,甚至可以將兩者混合,帶來意想不到的應用效果。 Downcodes小編將帶您深入了解SPIRIT LM的強大功能及其背後的技術突破。
Meta AI近日重磅開源了名為SPIRIT LM的基礎多模態語言模型,該模型能夠自由混合文字和語音,為音訊和文字的多模態任務開啟了新的可能性。
SPIRIT LM基於70億參數的預訓練文字語言模型,透過在文字和語音單元上進行持續訓練,擴展到語音模態。它可以像文本大模型一樣理解和生成文本,同時還能理解和生成語音,甚至可以把文本和語音混合在一起,創造出各種神奇的效果! 比如,你可以用它來做語音識別,把語音轉換成文字;也可以用它來做語音合成,把文字轉換成語音;還可以用它來做語音分類,判斷一段語音表達的是什麼情緒。
更厲害的是,SPIRIT LM 也特別擅長「情緒表達」! 它可以辨識和產生各種不同的語音語調和風格,讓AI 的聲音聽起來更自然、更有感情。 你可以想像一下,用SPIRIT LM 生成的語音,不再是那種冷冰冰的機器音,而是像真人說話一樣,充滿了喜怒哀樂!
為了讓AI 更好地“聲情並茂”,Meta 的研究人員還專門開發了兩個版本的SPIRIT LM:
「基礎版」 (BASE):這個版本主要關注語音的音素訊息,也就是語音的「基本構成」。
「表達版」(EXPRESSIVE): 這個版本除了音素訊息,還加入了音調和風格訊息,可以讓AI 的聲音更生動、更有表現力。
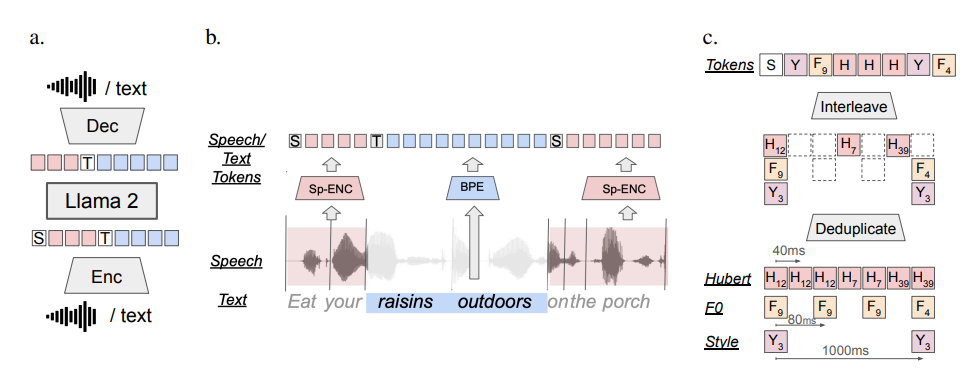
那麼,SPIRIT LM 又是如何做到這一切的呢?
簡單來說,SPIRIT LM 是基於Meta 之前發布的超強文本大模型——LLAMA2訓練出來的。 研究人員把大量的文字和語音資料「餵」給LLAMA2,並採用了一種特殊的「交錯訓練」方法,讓LLAMA2能夠同時學習文本和語音的規律。
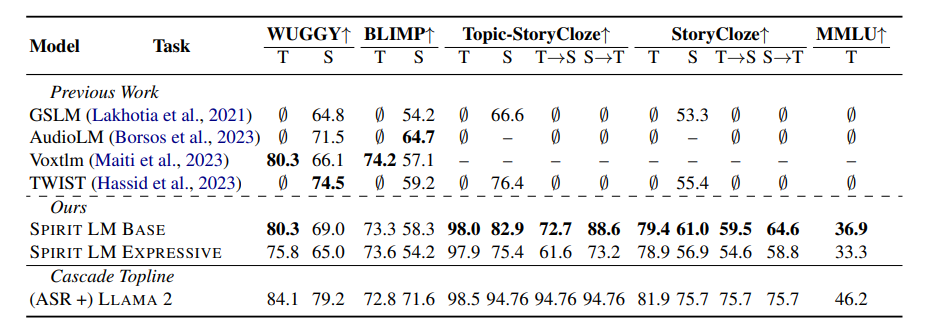
為了測試SPIRIT LM 的「情感表達」能力,Meta 的研究人員還專門設計了一個新的測試基準 –「語音-文字情感保留基準」(STSP)。 這個測驗基準包含了各種表達不同情緒的語音和文字提示,用來測試AI 模型是否能準確地辨識和產生對應情緒的語音和文字。 結果表明,SPIRIT LM 的「表達版」在情感保留方面表現出色,是目前第一個能夠跨模態保留情感訊息的AI 模型!
當然,Meta 的研究人員也坦言,SPIRIT LM 還有很多需要改進的地方。 例如,SPIRIT LM 目前只支援英文,未來還需要擴展到其他語言;SPIRIT LM 的模型規模還不夠大,未來還需要繼續擴大模型規模,提升模型效能。
SPIRIT LM 是Meta 在AI 領域的一項重大突破,它為我們打開了通往「聲情並茂」的AI 世界的大門。 相信在不久的將來,我們會看到更多基於SPIRIT LM 開發的有趣應用,讓AI 不止能說會道,還能像真人一樣表達情感,與我們進行更自然、更親切的交流!
專案地址:https://speechbot.github.io/spiritlm/
論文網址:https://arxiv.org/pdf/2402.05755
總而言之,SPIRIT LM 的開源為多模態AI領域帶來了令人興奮的進展,它的出現預示著未來AI在語音互動和情感表達方面將取得更大的突破,Downcodes小編將持續關注該領域的最新動態,敬請期待!