大型語言模型(LLM)的快速發展令人矚目,但僅僅追求模型規模的擴大並不足以實現真正的AI智慧。 Downcodes小編認為,賦予模型自我進化的能力,使其能夠在推理階段持續學習和改進,對AI的未來發展至關重要。本文將探討AI自我演化中的關鍵因素-長期記憶(LTM),以及如何透過LTM實現AI的持續進步。
大型語言模型(LLM)如GPT系列,憑藉龐大的數據集,在語言理解、推理和規劃方面展現出驚人的能力,在各種挑戰性任務中已達到與人類相當的水平。大多數研究都集中在透過在更大的資料集上訓練這些模型來進一步增強它們,目標是開發更強大的基礎模型。
然而,雖然訓練更強大的基礎模型至關重要,但研究人員認為,賦予模型在推理階段也能持續進化的能力,即AI自我進化,對AI的發展同樣至關重要。與使用大規模資料訓練模型相比,自我進化可能只需要有限的資料或交互作用。
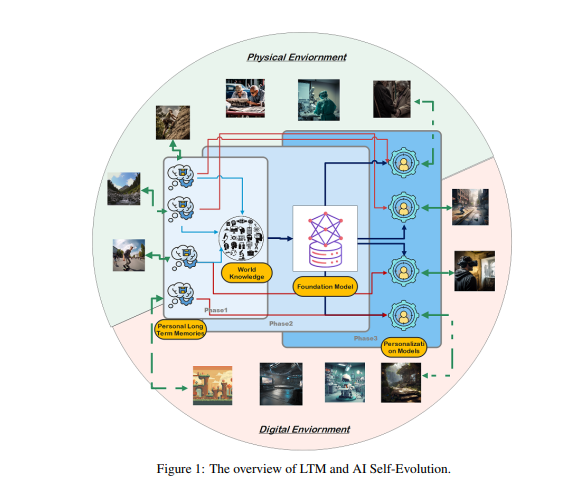
受人類大腦皮質柱狀結構的啟發,研究人員假設AI模型可以透過與其環境的迭代交互,發展出湧現的認知能力並建構內部表徵模型。
為實現這一目標,研究人員提出模型必須具備長期記憶(LTM),用於儲存和管理處理後的現實世界互動資料。 LTM不僅能夠在統計模型中表示長尾個體數據,還能透過支持跨越各種環境和代理的不同體驗來促進自我演化。
LTM是實現AI自我進化的關鍵。 類似於人類透過個人經驗和與環境的互動不斷學習和改進,AI模型的自我演化也依賴在互動過程中累積的LTM資料。不同於人類的演化,LTM驅動的模型演化不限於現實世界的互動。模型可以像人類一樣與物理環境互動並接收直接回饋,這些回饋經過處理後將增強其能力,這也是具身AI的關鍵研究領域。
另一方面,模型也可以在虛擬環境中進行互動並累積LTM數據,與現實世界互動相比,這具有更低的成本和更高的效率,從而更有效地增強能力。
建構LTM需要將原始資料進行提煉和結構化。 原始資料是指模型透過與外部環境的交互作用或在訓練過程中接收到的所有未處理資料的集合。 這些數據包含各種觀察結果和記錄,其中可能包含有價值的模式和大量冗餘或不相關的資訊。
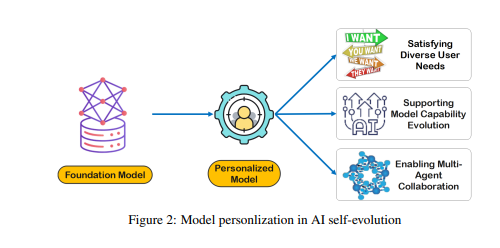
雖然原始資料構成了模型記憶和認知的基礎,但需要進一步處理才能有效地用於個人化或有效率地執行任務。 LTM將這些原始資料提煉和結構化,使模型可以使用它們。這個過程增強了模型提供個人化回應和建議的能力。
建構LTM面臨資料稀疏性和使用者多樣性等挑戰。 在持續更新的LTM系統中,資料稀疏性是一個常見問題,特別是對於互動歷史有限或活動零散的使用者而言,這使得模型訓練變得困難。 此外,使用者多樣性也增加了複雜性,要求模型既要適應個體模式,又要有效地跨越不同的使用者群體進行泛化。
研究人員開發了一個名為Omne的多代理協作框架,該框架基於LTM實現了AI自我進化。 在這個框架中,每個代理人都有一個獨立的系統結構,可以自主學習和儲存一個完整的環境模型,從而建構對環境的獨立理解。 透過這種基於LTM的協作開發,AI系統可以即時適應個體行為的變化,優化任務規劃和執行,進一步促進個人化和高效的AI自我進化。
Omne框架在GAIA基準測試中取得了第一名的成績,證明了利用LTM進行AI自我進化和解決現實世界問題的巨大潛力。 研究人員相信,推進LTM的研究對於AI技術的持續發展和實際應用至關重要,尤其是在自我進化方面。
總而言之,長期記憶是AI自我進化的關鍵,它使AI模型能夠像人類一樣從經驗中學習和改進。 建構和利用LTM需要克服資料稀疏性和使用者多樣性等挑戰。 Omne框架為基於LTM的AI自我進化提供了一個可行的方案,其在GAIA基準測試中的成功表明了該領域的巨大潛力。
論文:https://arxiv.org/pdf/2410.15665
透過長期記憶(LTM)的研究,AI自我進化不再是遙不可及的夢。 未來,基於LTM的AI模型有望在更廣泛的領域展現出更強大的能力,為人類社會帶來更大的福祉。 期待更多創新成果的出現!