卡內基美隆大學的研究團隊最近發布了一項突破性技術—DressRecon,這項技術能夠透過單眼視訊重建時間一致且細節豐富的人體3D模型。有別於以往需要緊身衣物或多視角資料的人體重建方法,DressRecon能夠處理穿著寬鬆衣物甚至手持物體的場景,大大擴展了應用範圍,為虛擬形象創建、動畫製作等領域帶來革新。 Downcodes小編帶你深入了解這項令人矚目的技術。
近日,卡內基美隆大學的研究團隊發布了一項名為「DressRecon」的新技術,旨在透過單眼影片重建時間一致的人體模型。 DressRecon的厲害之處在於,不僅輸入影片就能實現建構出3D模型,並且它還能還原複雜的服裝和手持物品等細微細節。
這項技術特別適用於穿著寬鬆衣物或與手持物互動的場景,突破了以往技術的限制。過去的人體重建通常要求穿著緊身衣物,或需要多視角校準捕捉數據,甚至個人化掃描,難以大規模收集。
而「DressRecon」的創新在於它結合了通用的人體形態先驗知識和特定影片的形體變形,能夠在一段影片中進行最佳化。
這項技術的核心是學習一個神經隱式模型,該模型能夠將身體和衣物的變形分開處理,分別建立運動模型層。
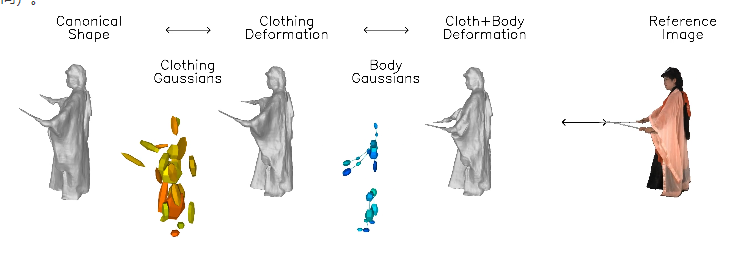
為了捕捉衣物的細微幾何特徵,研究團隊利用了影像基礎的先驗知識,包括人體姿態、表面法線和光流等。這些資訊在優化過程中提供了額外的支持,使得重建的效果更加真實。

DressRecon 能夠從單一的視訊輸入中提取出高保真的三維模型,甚至能透過進一步優化為明確的三維高斯體,以提高渲染質量,支援互動式視覺化。
研究者展示了在一些極具挑戰性的衣物變形和物件互動的資料集上,DressRecon 所能實現的高保真三維重建效果。
此外,重建的虛擬人形象能夠從任意角度進行渲染,展現出極具視覺衝擊力的效果。團隊也比較了DressRecon 與多個基線技術在形狀重建上的表現,結果表明,DressRecon 在處理複雜變形結構時,展現出了更高的保真度。
計畫入口:https://jefftan969.github.io/dressrecon/
劃重點:
? 研究團隊推出DressRecon 技術,透過單眼影片實現高品質的人體重建,尤其適用於寬鬆衣物和手持物件的場景。
? 利用神經隱式模型,此技術將身體與衣物變形分開處理,借助影像基礎的先驗知識來捕捉細微幾何特徵。
? 重建結果不僅能產生高保真的三維模型,還支援從任意角度渲染,提升了視覺化體驗。
DressRecon技術的出現,無疑將推動三維人體建模技術向前發展一大步。其高效、便利的特性,以及對複雜場景的出色處理能力,為未來虛擬實境、動畫製作、遊戲開發等領域帶來了無限可能。期待這項技術在更多應用場景中發揮其巨大潛力!