清華校友團隊借助AI,取得了令人矚目的數學突破!他們開發的LeanAgent,一個具備終身學習能力的AI助手,成功證明了162個以前未解的數學定理,甚至攻克了陶哲軒提出的多項式Freiman-Ruzsa猜想的形式化難題。這不僅展示了AI在基礎科學研究中的巨大潛力,也標誌著數學研究方法的革新。 Downcodes小編將帶您深入了解這項令人興奮的進展,以及LeanAgent背後的技術創新。
在最新的數學界轟動新聞中,一群來自清華的校友們藉助AI 的力量,成功證明了162個之前無人能解的數學定理。更厲害的是,這個名叫LeanAgent 的智能體,竟然還攻克了陶哲軒對多項式Freiman-Ruzsa 猜想的形式化難題!這讓我們不得不感嘆,基礎科學的研究方法可謂是被AI 徹底改頭換面了。
眾所周知,目前的語言模型(LLM)雖然酷炫,但大多依然是靜態的,無法在線上學習新知識,證明高等數學定理更是難如登天。然而,加州理工、史丹佛大學和華盛頓大學的研究團隊共同開發的LeanAgent,正是一個具備終身學習能力的AI 助手,能夠不斷學習和證明定理。
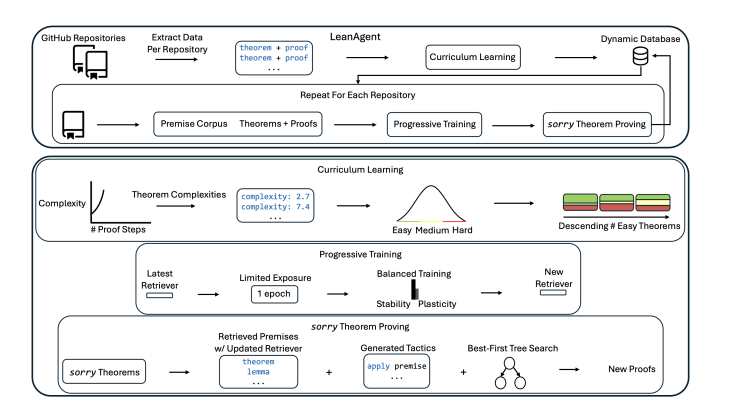
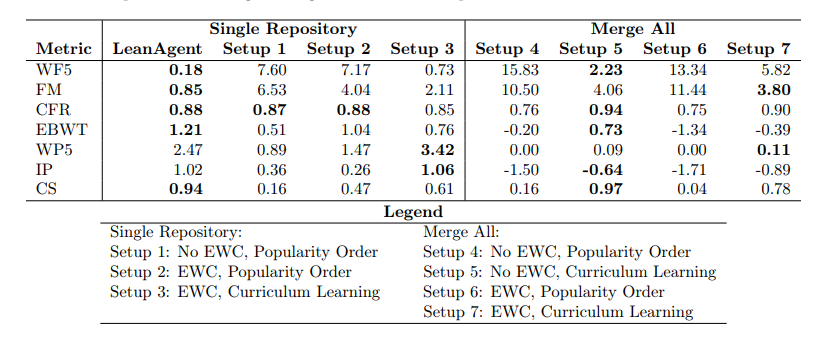
LeanAgent 透過精心設計的學習路徑來應對不同數學難度,利用動態資料庫管理源源不絕的數學知識,確保它在學習新知識時不會忘記已經掌握的技能。實驗表明,它成功從23個不同的Lean 程式碼庫中,證明了162個此前無人能解的數學定理,性能比傳統的大模型高出了整整11倍,真是令人驚嘆!
這些定理涵蓋了高等數學的許多領域,包括抽象代數和代數拓樸等棘手的問題。 LeanAgent 不僅能夠從簡單概念入手,逐漸攻克複雜主題,還在穩定性和反向遷移方面展現了卓越的表現。
不過,陶哲軒的挑戰依然讓AI 感到無奈。儘管互動式定理證明器(ITPs)如Lean,在形式化和驗證數學證明方面發揮重要作用,但建構這樣的證明過程往往複雜且耗時,需細緻入微的步驟和大量數學程式碼庫。像o1和Claude 這樣的先進大模型面對非形式化證明時,也容易出現錯誤,這突顯了LLM 在數學證明準確性和可靠性上的短板。
過去的研究嘗試了使用LLM 產生完整證明步驟,例如LeanDojo,就是透過訓練大模型在特定資料集上創建的定理證明器。然而,形式化定理所證明的數據極為稀缺,限制了這種方法的廣泛應用。另一個項目ReProver 則是針對Lean 定理證明程式碼庫mathlib4優化的模型,雖然它涵蓋了超過10萬個形式化數學定理和定義,但僅限於本科數學的範圍,因此在面對更複雜問題時表現不佳。
值得注意的是,數學研究的動態性為AI 帶來了更大挑戰。數學家通常同時或交替處理多個項目,例如陶哲軒同時推進多個研究領域,包括PFR 猜想和實數對稱平均等。這些例子顯示了當前AI 定理證明方法的一個關鍵不足:缺乏一個能夠在不同數學領域自適應學習和提升的AI 系統,尤其是在Lean 數據有限的情況下。
正因如此,LeanDojo 的團隊創造了LeanAgent,這是一個全新的終身學習框架,旨在解決上述難題。 LeanAgent 的工作流程包括推導定理複雜度,以建立學習課程,透過漸進訓練在學習過程中平衡穩定性與靈活性,並利用最佳優先樹搜尋來尋找尚未證明的定理。
LeanAgent 與任何大模型結合使用,透過「檢索」 來提升其泛化能力。它的創新之處在於使用自訂動態資料庫來管理不斷擴展的數學知識,以及基於Lean 證明結構的課程學習策略,以協助學習更複雜的數學內容。
在應對AI 的災難性遺忘問題上,研究者採用了一種漸進式訓練的方法,使LeanAgent 能夠持續適應新的數學知識,同時不忘記先前的學習。這個過程涉及在每個新的資料集上進行增量訓練,確保穩定性與靈活性達到最佳平衡。
透過這種漸進式訓練,LeanAgent 在證明定理方面的表現卓越,成功證明了162個尚未被人類解答的難題,尤其在抽象代數和代數拓樸的挑戰性定理上大展身手。其在證明新定理的能力上比靜態的ReProver 高出11倍,且維持了已知定理的證明能力。
LeanAgent 在定理證明的過程中展現了漸進學習的特徵,從簡單的定理逐漸過渡到更複雜的定理,證明了它在數學知識掌握上的深度。例如,它證明了與群論和環論相關的基礎代數結構定理,展現出對數學的深刻理解。總的來看,LeanAgent 以其強大的持續學習和改進能力,為數學界帶來了令人興奮的前景!
論文網址:https://arxiv.org/pdf/2410.06209
LeanAgent 的出現,預示著AI在數學研究領域將發揮越來越重要的作用,未來或將出現更多藉助AI力量解決複雜數學問題的案例。 這無疑為數學研究開啟了新的方向,也為其他科學領域的探索提供了新的思路和方法。期待未來有更多令人驚嘆的成果出現!