在資訊爆炸的時代,高效處理圖像中的文字訊息至關重要。 Downcodes小編今天要介紹一款革命性的OCR模型-GOT(通用光學字元辨識理論),它標誌著OCR技術進入2.0時代。 GOT模型融合了傳統OCR和大型語言模型的優勢,以其強大的性能和全能性,為文本識別領域帶來了新的突破。它不僅能辨識英文和中文文件及場景文本,還能處理數學化學公式、音樂符號、圖表等複雜訊息,堪稱OCR領域的「全能選手」。
在數位化時代,將圖像中的文字內容快速轉換成可編輯文字是一個常見且重要的需求。現在,一項名為GOT(通用光學字元辨識理論)的新型光學字元辨識(OCR)模型的問世,標誌著OCR技術邁入了2.0時代。這項創新模型結合了傳統OCR系統與大型語言模式的優勢,旨在打造一個更有效率、更聰明的文字辨識工具。
GOT模型採用了創新的端到端架構,這項設計不僅節省資源,還大大擴展了辨識能力,使其不僅限於文字辨識。該模型由一個參數約8000萬的圖像編碼器和一個參數約500萬的解碼器組成。影像編碼器能夠將高達1024x1024像素的影像壓縮成資料單元,而解碼器則將這些資料轉換為長達8000字元的文字。
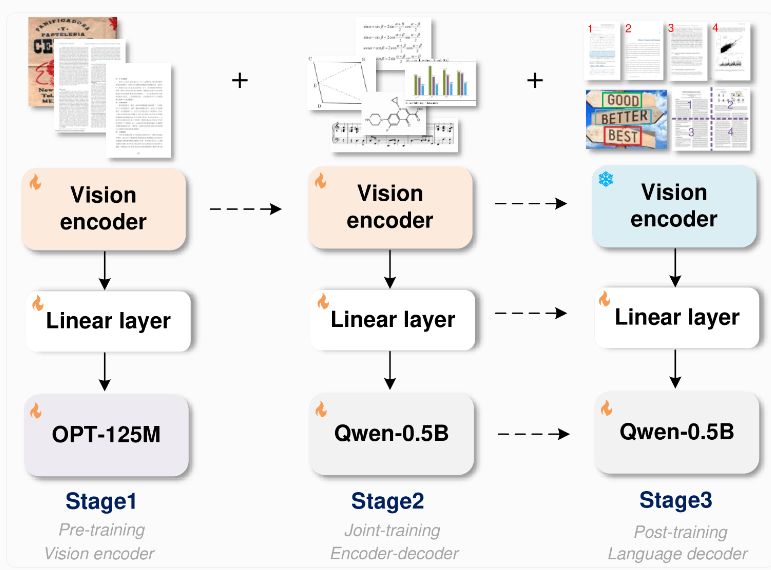
GOT的強大之處在於其全能性,不僅能辨識轉換英文和中文文件及場景文本,還能處理數學化學公式、音樂符號、簡單幾何圖形及各種圖表。這使得GOT成為一個真正的多面手。
為了訓練這個模型,研究團隊首先集中在文字辨識任務,然後採用阿里巴巴的Qwen-0.5B作為解碼器,並透過多種合成資料進行微調。他們使用LaTeX、Mathpix-markdown-it和Matplotlib等專業渲染工俱生成了數百萬個圖像-文字對,用於模型訓練。

OCR2.0技術的另一個亮點是其能夠提取格式化文字、標題,甚至多頁影像,並將其轉換為結構化的數位格式。這為科學、音樂和數據分析等領域的自動處理和分析提供了新的可能性。
在各種OCR任務的測試中,GOT展現了卓越的性能,在文件和場景文本識別方面取得了行業領先成績,甚至在圖表識別方面也超越了許多專業模型和大型語言模型。無論是複雜的化學結構公式,或是音樂符號和資料視覺化,OCR2.0都能準確捕捉並轉換為機器可讀格式。
為了讓更多用戶能夠體驗並利用這項技術,研究團隊在Hugging Face平台上發布了免費的演示和程式碼。 OCR2.0的到來,無疑為資訊處理領域帶來了一場革命,它不僅提高了效率,還增加了靈活性,讓我們對圖像中的文字訊息處理更加得心應手。
GOT模型的出現,無疑為OCR技術注入了新的活力,其高效、精準、全能的特性將廣泛應用於各行各業,為人們的工作和生活帶來更多便利。期待未來GOT模型能進一步完善,為我們帶來更多驚喜!