Downcodes小編獲悉,伊利諾理工學院等多所大學的研究團隊共同發表了全新的3D場景大語言模式Robin3D。該模型在包含百萬條指令的大規模資料集上訓練,並在五個常用3D多模態學習基準測試中取得了當前最佳效能。 Robin3D的創新之處在於其數據引擎RIG,它能夠產生對抗性和多樣化指令數據,從而提升模型的辨別理解和泛化能力,克服了現有3D大語言模型泛化能力不足和過度擬合的缺陷。它還整合了關係增強投影機(RAP)和ID特徵綁定(IFB)等技術,增強了模型對場景和物件的理解。
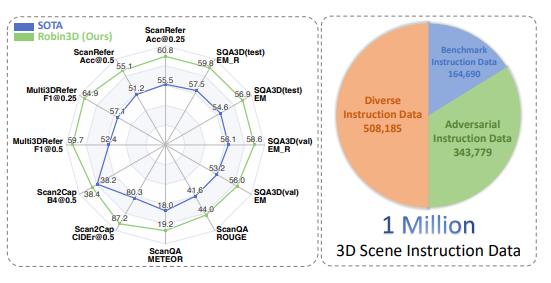
該模型在包含一百萬條指令遵循資料的大規模資料集上進行訓練,並在五個常用的3D多模態學習基準測試中均取得了當前最佳的性能表現,標誌著在構建通用3D智能體方向上的重大進步。
Robin3D的成功得益於其創新的資料引擎RIG (Robust Instruction Generation)。 RIG引擎旨在產生對抗性指令遵循資料和多樣化指令遵循資料兩種關鍵指令資料。
對抗性指令遵循資料透過混合正負樣本來增強模型的辨別理解能力,而多樣化指令遵循資料則包含各種指令風格以增強模型的泛化能力。
研究人員指出,現有的3D大語言模型主要依賴正面的3D視覺語言配對和基於模板的指令進行訓練,這導致了泛化能力不足和過度擬合的風險。 Robin3D透過引入對抗性和多樣化的指令數據,有效地克服了這些限制。
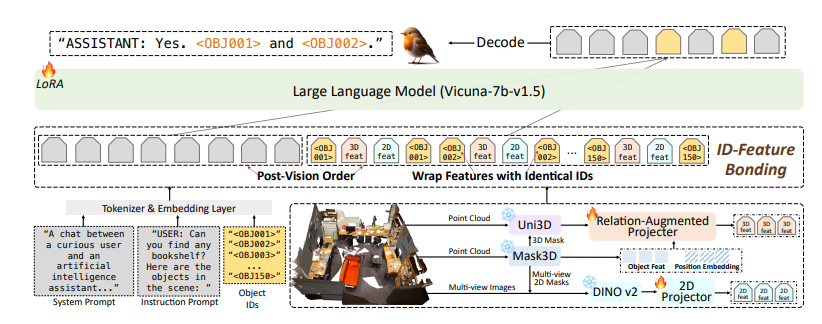
Robin3D模型也整合了關係增強投影機(RAP)ID特徵綁定(IFB)指稱和定位能力。 RAP模組透過豐富的場景層級上下文和位置資訊來增強以物件為中心的特徵,而IFB模組則透過將每個ID與其對應的特徵綁定來加強它們之間的連接。
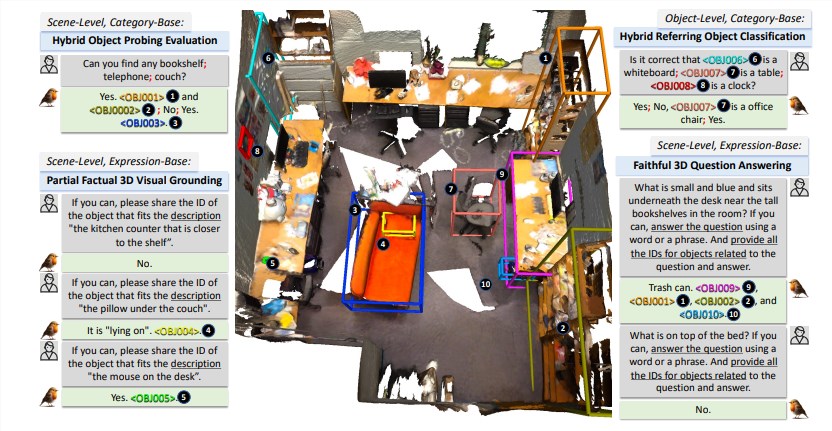
實驗結果表明,Robin3D在無需針對特定任務進行微調的情況下,在包括ScanRefer、Multi3DRefer、Scan2Cap、ScanQA和SQA3D在內的五個基準測試中均超越了之前的最佳方法。
尤其是在包含零目標案例的Multi3DRefer評估中,Robin3D在[email protected]和[email protected]指標上分別取得了7.8%和7.3%的顯著提升。
Robin3D的發布標誌著3D大語言模型在空間智能方面取得了重大進步,為未來構建更加通用和強大的3D智能體奠定了堅實的基礎。
論文網址:https://arxiv.org/pdf/2410.00255
Robin3D的出現,無疑為3D視覺和人工智慧領域帶來了新的突破,其強大的性能和廣泛的應用前景值得期待。相信未來,Robin3D將在更多領域發揮作用,推動3D智能體的快速發展。 Downcodes小編將持續關注該領域的最新進展。