Downcodes小編帶您了解阿里巴巴AI團隊的最新突破!他們推出的mPLUG-DocOwl1.5模型在無需OCR技術的情況下,實現了卓越的文檔理解能力。該模型打破了傳統文件理解的瓶頸,直接從圖像中學習理解文件內容,其高效性和準確性令人驚嘆。它不僅能夠處理普通文檔,還支援表格、圖表、網頁和自然圖像等多種文檔類型,展現出強大的適應性和處理能力。讓我們一起來深入了解這款尖端AI模型的優勢和未來發展方向。
最近,阿里巴巴的AI 研究團隊在文檔理解領域取得了令人矚目的進展,他們推出了mPLUG-DocOwl1.5,這是一款在無OCR(光學字元辨識)文檔理解任務上表現卓越的尖端模型。
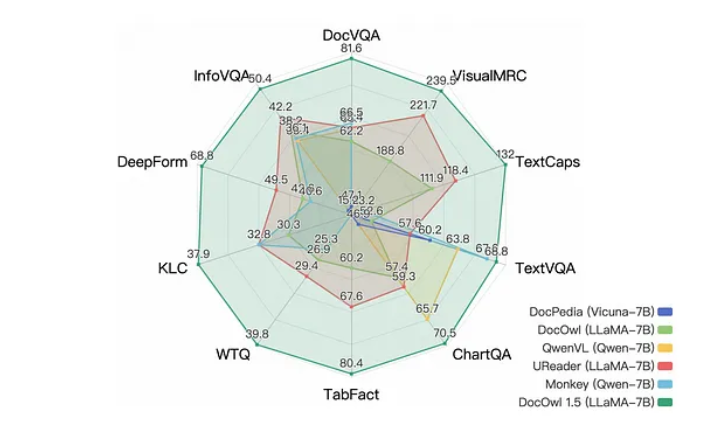
過去,在處理文件理解任務時,我們通常依賴OCR 技術來從圖像中提取文本,但這往往會受到複雜佈局和視覺噪聲的困擾。而mPLUG-DocOwl1.5則透過一種全新的統一結構學習框架,直接從圖像中學習理解文檔,巧妙地避開了這一瓶頸。
該模型透過分析文件在不同領域的佈局和組織能力,涵蓋了普通文件、表格、圖表、網頁和自然圖像等五個領域。它不僅能準確辨識文字,還能在理解文件結構時,運用空格和換行符等元素。

對於表格,模型能產生結構化的Markdown 格式,而在解析圖表時,它透過理解圖例、座標軸和數值之間的關係,將其轉換為資料表。此外,mPLUG-DocOwl1.5也具備從自然圖像中提取文字的能力。
在文字本地化方面,mPLUG-DocOwl1.5能夠識別和定位單字、短語、行和區塊,確保文字與圖像區域之間的精確對齊。而背後的H-Reducer 架構則透過卷積操作橫向合併視覺特徵,維持空間佈局的同時減少序列長度,從而提升了處理效率。
為了訓練這個模型,研究團隊使用了兩個精心挑選的資料集。 DocStruct4M 是一個大規模的資料集,專注於統一結構學習,DocReason25K 則透過逐步問答來測試模型的推理能力。
結果顯示,mPLUG-DocOwl1.5在十個基準測試中創下了新紀錄,相比同類模型在一半任務上獲得了超過10分的提升。此外,它還展現出優秀的語言推理能力,能夠為其答案產生詳細的逐步解釋。
儘管mPLUG-DocOwl1.5在多個方面都取得了顯著進展,但研究者也意識到,模型仍有改進空間,尤其是在處理不一致或錯誤的陳述方面。未來,團隊希望能夠進一步擴展統一結構學習框架,涵蓋更多的文件類型和任務,推動文件AI 的進一步發展。
論文:https://arxiv.org/abs/2403.12895
代碼:https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
劃重點:
mPLUG-DocOwl1.5是一在無需OCR 文檔理解任務上表現卓越的AI 模型。
此模型能分析文件佈局,涵蓋多種文件類型,能夠從影像中直接學習理解。
mPLUG-DocOwl1.5在十個基準測試中創下新紀錄,展現出優越的語言推理能力。
mPLUG-DocOwl1.5的出現,標誌著文檔理解技術邁向了一個新的里程碑。其高效、準確以及強大的適應性,為未來文件處理和資訊擷取提供了無限可能。 Downcodes小編相信,隨著科技的不斷進步,mPLUG-DocOwl1.5將會在更多領域發揮重要作用,為我們帶來更智慧的資訊處理體驗。