Downcodes小編獲悉,Stability AI發布了其最新、最強大的圖像生成模型Stable Diffusion 3.5,該模型並非單一版本,而是包含三個版本,以滿足不同用戶的需求,從科研人員到企業用戶都能從中獲益。這三個版本在參數量、運行速度和適用硬體方面各有側重,為用戶提供了更廣泛的選擇。
昨日晚間,Stability AI發布了其最強大的模型——Stable Diffusion3.5,這不僅是一個單一的模型,而是一個包含三個版本的全家桶,旨在滿足從科研人員到業務愛好者、新創公司和企業的多樣化需求。
這三個版本分別是Stable Diffusion3.5Large、Stable Diffusion3.5Large Turbo和即將於10月29日發布的Stable Diffusion3.5Medium。
Stable Diffusion3.5Large是一個擁有80億參數的基礎模型,以其卓越的圖像品質和提示詞精確度而著稱,非常適合專業用途,能夠生成高達1百萬像素分辨率的圖像。
Stable Diffusion3.5Large Turbo是前者的蒸餾版本,它能夠在僅4步內生成高品質影像,生成速度遠快於Stable Diffusion3.5Large。
而Stable Diffusion3.5Medium則擁有25億參數,採用改良的MMDiT-X架構與訓練方法,設計為即插即用,能夠在消費級硬體上直接運行,平衡了影像品質與可自訂性,能夠產生分辨率在0.25到2百萬像素之間的影像。
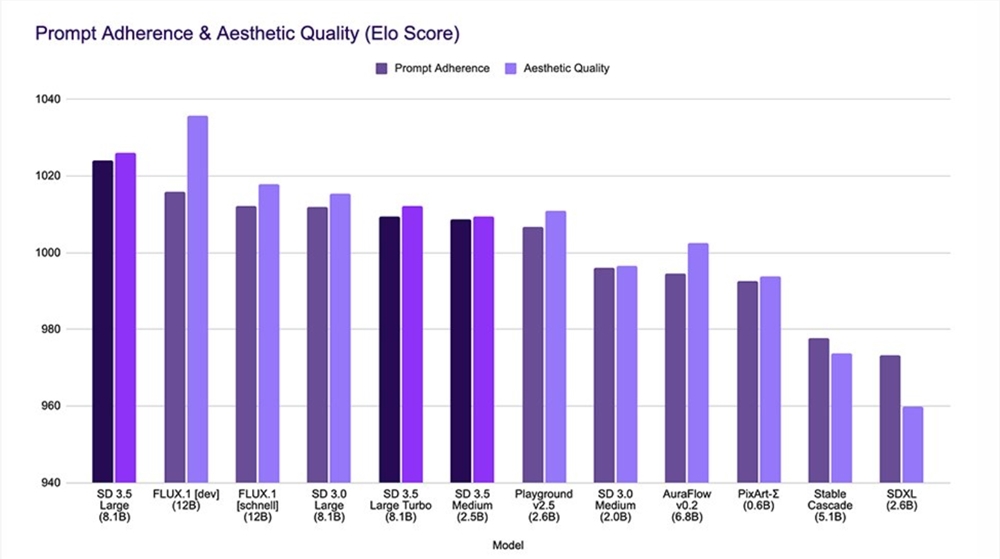
這些模型的開發優先考慮了可自訂性,透過將Query-Key Normalization整合到transformer區塊中,穩定了模型訓練過程並簡化了進一步的微調和開發。為了支援下游任務的靈活性,Stability AI在模型中保留了更廣泛的知識基礎和多樣化的風格,儘管這可能導致輸出結果的不確定性增加。
Stable Diffusion3.5模型在多個方面表現出色,包括可自訂性、高效性能和多樣化輸出。這些模型能夠輕鬆微調以滿足特定創作需求,或根據客製化的工作流程建立應用程式。它們也經過最佳化,可在標準消費級硬體上運行,無需過高的硬體需求。此外,這些模型能夠創造代表全世界的圖像,無需大量的提示詞,同時能夠產生各種風格和美感的圖片,如3D、攝影、繪畫、線條藝術以及幾乎任何可以想像到的視覺風格。


Stability AI也強調了其對安全的承諾,採取了合理的措施防止Stable Diffusion3.5被濫用,並從開發早期階段就注重完整性。此外,Stability AI社群許可非常寬鬆,允許個人和組織免費使用該模型進行非商業用途,包括科學研究。對於年收入不超過100萬美元的新創公司、中小型企業和創作者,也可以免費將該模型用於商業用途。保留產生媒體的所有權,無需受到限制性許可的影響。
Stable Diffusion3.5模型已經在Hugging Face上可供自架使用,推理程式碼也已經開源。此外,還可以透過Stability AI API、Replicate、ComfyUI和DeepInfra等平台存取模型。
體驗網址: https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-large
總而言之,Stable Diffusion 3.5系列模型在影像品質、生成速度和易用性方面取得了顯著進展,為使用者提供了強大的影像生成能力和靈活的應用場景。 Downcodes小編建議各位讀者前往體驗,感受其強大的表現。