隨著AIGC技術的快速發展,影像竄改日益猖獗,傳統的影像竄改偵測和定位方法(IFDL)面臨「黑盒子」性質和泛化能力不足的挑戰。 Downcodes小編獲悉,北京大學研究團隊提出了一個名為FakeShield的多模態框架,旨在解決這些難題。 FakeShield巧妙地利用了大型語言模型(LLM)的強大能力,特別是多模態大型語言模型(M-LLM),透過建構多模態篡改描述資料集(MMTD-Set)並對模型進行微調,實現了對各種篡改技術的有效檢測和定位,並提供可解釋的分析結果。
隨著AIGC技術的快速發展,影像編輯工具日益強大,影像竄改變得更加容易,也更難被察覺。 雖然現有的影像篡改偵測和定位方法(IFDL)通常很有效,但它們往往面臨兩大挑戰:一是「黑盒子」性質,偵測原理不明;二是泛化能力有限,難以應對多種篡改方法(如Photoshop、DeepFake、AIGC編輯)。
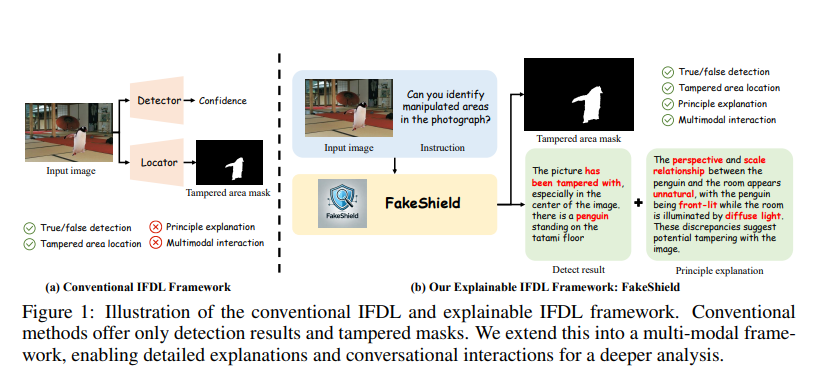
為解決這些問題,北京大學的研究團隊提出了可解釋的IFDL任務,並設計了FakeShield,這是一個多模態框架,能夠評估影像的真實性,產生篡改區域掩碼,並基於像素級和影像級的篡改線索提供判斷依據。
傳統的IFDL方法只能提供影像的真實性機率和竄改區域,而無法解釋偵測原理。 由於現有IFDL方法的準確性有限,仍需要人工進行後續判斷。 但由於IFDL方法提供的資訊不足,難以支援人工評估,使用者仍需要自行重新分析可疑影像。
此外,在現實場景中,篡改類型多種多樣,包括Photoshop(複製移動、拼接和移除)、AIGC編輯、DeepFake等。 現有的IFDL方法通常只能處理其中一種技術,缺乏全面的泛化能力。 這迫使使用者事先識別不同的篡改類型,並相應地應用特定的檢測方法,大大降低了這些模型的實用性。
為解決現有IFDL方法的這兩大問題,FakeShield框架利用了大型語言模型(LLM)的強大能力,特別是多模態大型語言模型(M-LLM),它能夠對齊視覺和文字特徵,從而賦予LLM更強的視覺理解能力。 由於LLM在海量且多樣化的世界知識語料庫上進行了預訓練,因此它們在機器翻譯、程式碼補全和視覺理解等眾多應用領域都具有巨大的潛力。
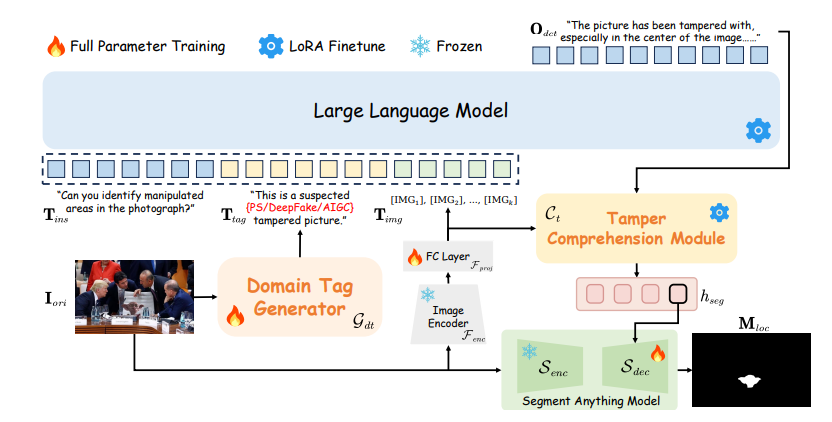
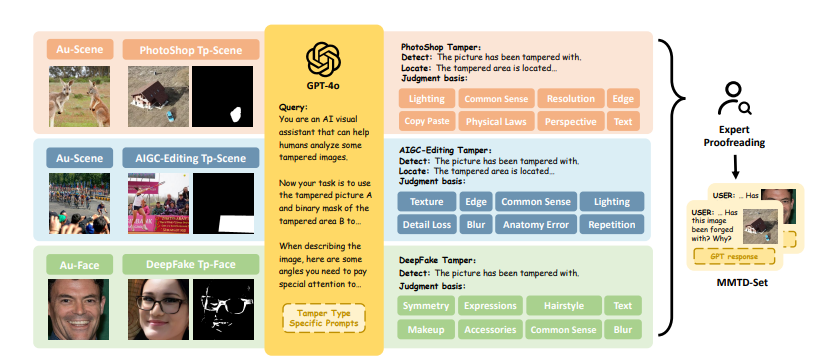
FakeShield框架的核心是多模態篡改描述資料集(MMTD-Set)。 此資料集利用GPT-4o對現有IFDL資料集進行了增強,包含了篡改影像、修改區域遮罩和編輯區域詳細描述的三元組。 透過利用MMTD-Set,研究團隊對M-LLM和視覺分割模型進行了微調,使其能夠提供完整的分析結果,包括偵測篡改和產生準確的篡改區域遮罩。
FakeShield還包含領域標籤引導的可解釋偽造檢測模組(DTE-FDM)多模態偽造定位模組(MFLM),分別用於解決各種類型的篡改檢測解釋和實現由詳細文本描述引導的偽造定位。
大量實驗表明,FakeShield可以有效地檢測和定位各種篡改技術,與以往的IFDL方法相比,它提供了一種可解釋的、更優越的解決方案。
這項研究成果是將M-LLM應用於可解釋IFDL的首次嘗試,標誌著該領域取得了重大進展。 FakeShield不僅擅長竄改偵測,還能提供全面的解釋和精確定位,並展現出對各種竄改類型的強大泛化能力。 這些特性使其成為適用於各種現實應用的多功能實用工具。
未來,這項工作將在多個領域發揮至關重要的作用,例如幫助改善與數位內容操縱相關的法律法規,為生成式人工智慧的開發提供指導,以及促進更清晰、更值得信賴的網路環境。 此外,FakeShield還可以協助法律訴訟中的證據收集,並幫助糾正公眾話語中的錯誤訊息,最終有助於提升數位媒體的完整性和可靠性。
專案首頁:https://zhipeixu.github.io/projects/FakeShield/
GitHub網址:https://github.com/zhipeixu/FakeShield
論文網址:https://arxiv.org/pdf/2410.02761
FakeShield的出現為圖像篡改檢測領域帶來了新的突破,其可解釋性和強大的泛化能力使其在實際應用中具有巨大的潛力,值得期待其未來在維護網路安全和提升數位媒體可信度方面發揮更大作用。 Downcodes小編相信,這項技術將對數位內容的真實性和可靠性產生正面影響。