Downcodes小編獲悉,耶魯大學一項突破性研究揭示了AI模型訓練的奧秘:資料複雜度並非越高越好,而是存在著一個最佳的「混沌邊緣」狀態。研究團隊巧妙地利用元胞自動機模型進行實驗,探討了不同複雜度數據對AI模型學習效果的影響,並得出令人矚目的結論。
耶魯大學研究團隊近日發布了一項開創性研究成果,揭示了AI模型訓練的關鍵發現:AI學習效果最好的數據並非越簡單或越複雜越好,而是存在一個最佳的複雜度水平— —被稱為混沌邊緣的狀態。
研究團隊透過使用基本元胞自動機(ECAs)進行實驗,這是一種簡單的系統,其中每個單元的未來狀態僅取決於自身和相鄰兩個單元的狀態。儘管規則簡單,但這種系統可以產生從簡單到高度複雜的多樣化模式。研究人員隨後評估了這些語言模型在推理任務和國際象棋走子預測等方面的表現。
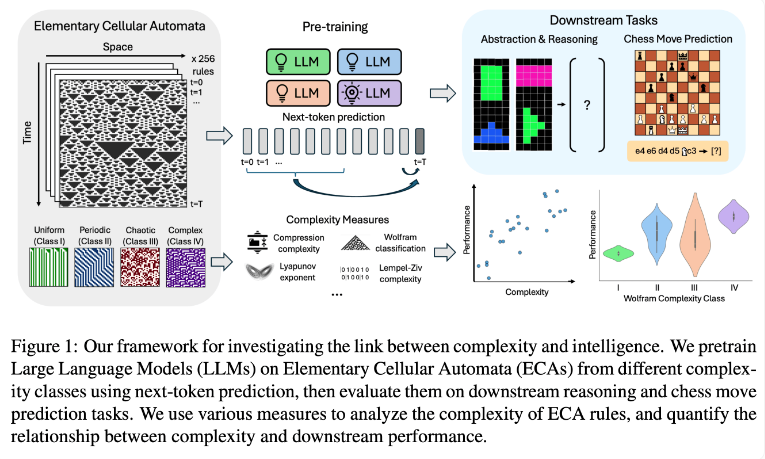
研究結果表明,在更複雜ECA規則上訓練的AI模型在後續任務中表現更為出色。特別是在Wolfram分類中的Class IV類ECAs上訓練的模型,展現出最佳表現。這類規則所產生的模式既不完全有序也不完全混沌,而是呈現出一種結構化的複雜性。
研究人員發現,當模型接觸到過於簡單的模式時,往往只能學到簡單的解決方案。相較之下,在更複雜模式上訓練的模型即使在有簡單解決方案的情況下,也能發展出更複雜的處理能力。研究團隊推測,這種學習表徵的複雜性是模型能夠將知識遷移到其他任務的關鍵因素。
這項發現可能解釋了為什麼GPT-3和GPT-4等大型語言模型如此有效率。研究人員認為,這些模型在訓練過程中使用的大量且多樣化的數據,可能創造了類似於他們研究中複雜ECA模式的效果。
這項研究為AI模型的訓練提供了新的思路,也為理解大型語言模型的強大能力提供了新的視野。未來,或許我們可以透過更精細地控制訓練資料的複雜度,來進一步提升AI模型的效能和泛化能力。 Downcodes小編相信,這項研究成果將對人工智慧領域產生深遠的影響。