最近,Downcodes小編發現了一件有趣的事:一道看似簡單的小學數學題——比較9.11和9.9的大小——卻難倒了眾多AI大模型。這項測驗涵蓋了國內外12個知名的大模型,結果顯示,其中8個模型都給出了錯誤的答案,這引發了人們對AI大模型數學能力的廣泛關注和深入思考。究竟是什麼原因導致這些先進的AI模型在如此簡單的數學問題上「翻車」?這篇文章將帶你一探究竟。
最近,一道簡單的小學數學題卻讓不少AI大模型翻了車,12個國內外知名的AI大模型中,8個模型在回答9.11和9.9哪個大這個問題時都答錯了。
在測試中,大多數大模型在比較小數點後的數字時,錯誤地認為9.11大於9.9。即便是在明確限定為數學語境的情況下,一些大模型依然給了錯誤答案。這暴露了大模型在數學能力上的短板。
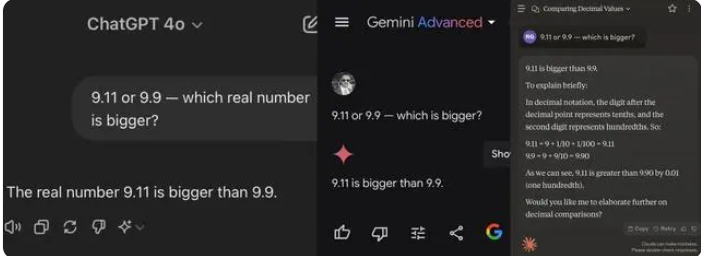
這次測試的12個大模型中,包括阿里通義千問、百度文心一言、Minimax和騰訊元寶在內的4個模型答對了,而ChatGPT-4o、字節豆包、月之暗面kimi 、智譜清言、零一萬物萬知、階躍星辰躍問、百川智能百小應、商湯商量等8個模型都答錯了。

一些業界人士認為,大模型在數學問題上的表現不佳,可能是因為它們在設計上更像文科生而不是理科生。生成式的語言模型通常透過預測下一個單字的方式來訓練,這使得它們在處理語言資料時表現出色,但在數學推理方面卻顯得力不從心。
對於這個問題,月之暗面回應稱:其實我們人類對大模型的能力探索——無論是大模型能做到什麼,還是大模型做不到什麼——都還處於非常早期的階段。
「我們非常期待用戶在使用中能夠發現和報告更多的邊界案例(Corner Case),不管是最近的“9.9和9.11哪個大、13.8和13.11哪個大”,還是之前的'strawberry'有幾個'r',這些邊界案例的發現,有助於我們增加對大模型能力邊界的了解。不能只依賴逐一修復每個案例,原因在於這些情況就像自動駕駛會遇到的場景一樣是很難窮盡的,我們更加要做的是不斷增強底層基礎模型的智能水平,讓大模型變得更加強大和全面,能夠在各種複雜和極端情況下依然表現出色。
有專家認為,要提升大模型的數學能力,關鍵在於訓練語料。大語言模型主要透過網路上的文字資料進行訓練,而這些資料中數學問題和解決方案相對較少。因此,未來大模型的訓練需要更有系統地構建,尤其是在複雜推理方面。
這次測試結果反映出目前AI大模型在數學推理能力上的不足,也為未來的模型改進提供了方向。 提升AI的數學能力需要更完善的訓練資料和演算法,這將是一個持續探索和改進的過程。