最近,一個看似簡單的數學比較問題「13.8和13.11哪個大?」卻難倒了不少人,甚至包括一些先進的AI模型。 Downcodes小編將帶你深入探討這一事件,分析AI在處理常識性問題上的不足,以及未來改進的方向。這不僅揭示了AI技術的局限性,也引發了人們對AI未來發展的思考。
最近,一個簡單的數學問題——13.8和13.11哪個大?——不僅難倒了部分人類,也讓許多大型語言模型(LLM)陷入了困境。這個問題引發了對AI在處理常識性問題上的能力的廣泛討論。
在一檔知名綜藝節目中,這個問題引發了網友的熱議。許多人認為13.11%應該比13.8%大,但事實上,13.8%更大。
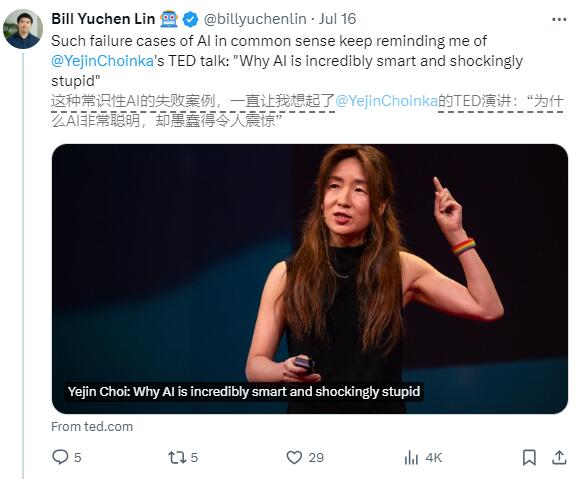
AI2的研究員林禹臣發現,即使是大型語言模型,如GPT-4o,也會在這個簡單的比較問題上犯錯。 GPT-4o錯誤地認為13.11比13.8大,並給了錯誤的解釋。
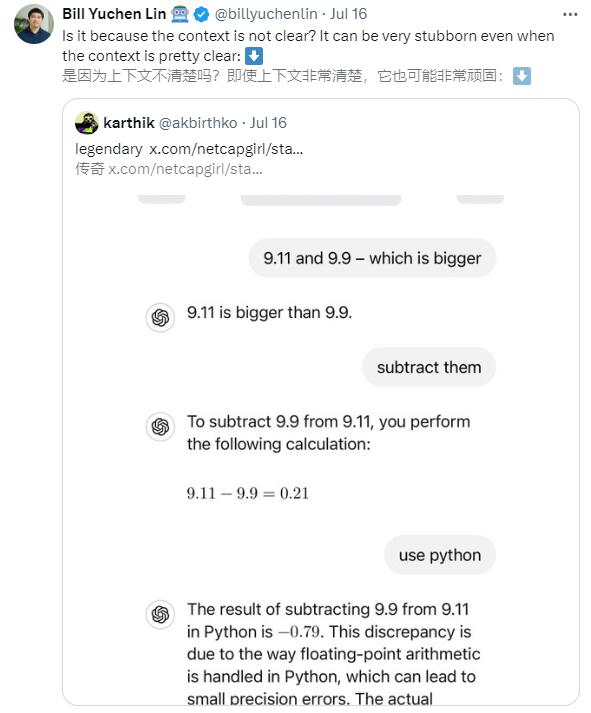
林禹臣的發現迅速在AI社群引起了熱烈討論。許多其他大型語言模型,如Gemini、Claude3.5Sonnet等,也在這個簡單的比較問題上犯了同樣的錯誤。
這個問題的出現揭示了AI在處理看似簡單但實際涉及精確數值比較的任務時可能遇到的困難。
儘管人工智慧在許多領域取得了顯著的進步,例如自然語言理解、圖像識別和複雜的決策等,但在基本的數學運算和邏輯推理方面,它們仍然可能犯錯,顯示出當前技術的局限性。
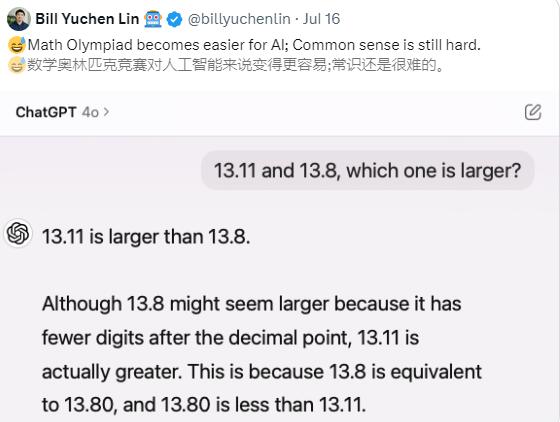
為什麼AI會犯這樣的錯誤?
訓練資料的偏差: AI模型的訓練資料可能沒有包含足夠的範例來正確處理這類特定的數值比較問題。如果模型在訓練期間接觸到的資料主要表明較大的數字總是有較多的小數位數,那麼它可能會錯誤地將更多的小數位解釋為更大的值。
浮點精度問題:在計算機科學中,浮點數的表示和計算涉及精度問題。即使是微小的差異也可能在比較時造成錯誤的結果,尤其是在沒有明確指定精度的情況下。
上下文理解不足:儘管上下文清晰度在這個案例中可能不是主要問題,但AI模型通常需要根據上下文來正確解釋資訊。如果問題的表述方式不夠明確或與AI在訓練資料中常見的模式不匹配,可能會導致誤解。
Prompt設計的影響:如何向AI提出問題對於獲得正確答案至關重要。不同的提問方式可能會影響AI的理解程度和回答的準確性。
如何改進?
改善訓練數據:透過提供更多樣化、更準確的訓練數據,可以幫助AI模型更好地理解數值比較和其他基本數學概念。
優化Prompt設計:精心設計的問題表述可以提高AI給出正確答案的機會。例如,使用更明確的數值表示和提問方式可以減少歧義。
提高數值處理的準確性:開發和採用能夠更準確處理浮點數運算的演算法和技術,以減少計算誤差。
增強邏輯和常識推理能力:透過專門針對邏輯和常識推理的訓練,增強AI在這些領域的能力,使其能夠更好地理解和處理與常識相關的任務。
總而言之,AI在處理簡單的數學比較問題上暴露出的缺陷,提醒我們AI技術仍處於發展階段,需要持續改進和完善。未來,透過優化訓練資料、改進演算法和增強邏輯推理能力,AI將在處理常識性問題方面取得更大的進步。