近年來,人工智慧技術的快速發展嚴重依賴海量資料的訓練。然而,Downcodes小編發現,MIT等機構的最新研究指出,取得數據的難度正在急遽增加。曾經輕易可得的網路數據,如今正受到越來越嚴格的限制,這對AI的訓練和發展帶來了巨大的挑戰。該研究對多個開源資料集進行了分析,揭示了這一嚴峻的現實。
在人工智慧的高速發展背後,一個嚴峻的問題正浮現——資料取得的難度正日益增加。 MIT等機構的最新研究發現,曾經輕易獲取的網頁數據,現在正變得越發難以訪問,這對AI的訓練和研究構成了重大挑戰。
研究人員發現,多個開源資料集如C4、RefineWeb、Dolma等,它們所爬取的網站正迅速收緊其授權協議。這不僅影響商業AI模式的訓練,也對學術和非營利組織的研究造成了阻礙。

這項研究由MIT Media Lab、Wellesley學院、AI新創公司Raive等機構的4位團隊主管共同進行。他們指出,數據的限制正在激增,且許可的不對稱性與不一致性問題日益凸顯。
研究團隊使用了機器人排除協議(Robots Exclusion Protocol, REP)和網站的服務條款(Terms of Service, ToS)作為研究方法。他們發現,即使是OpenAI這樣的大型AI公司的爬蟲,也面臨越來越嚴格的限制。
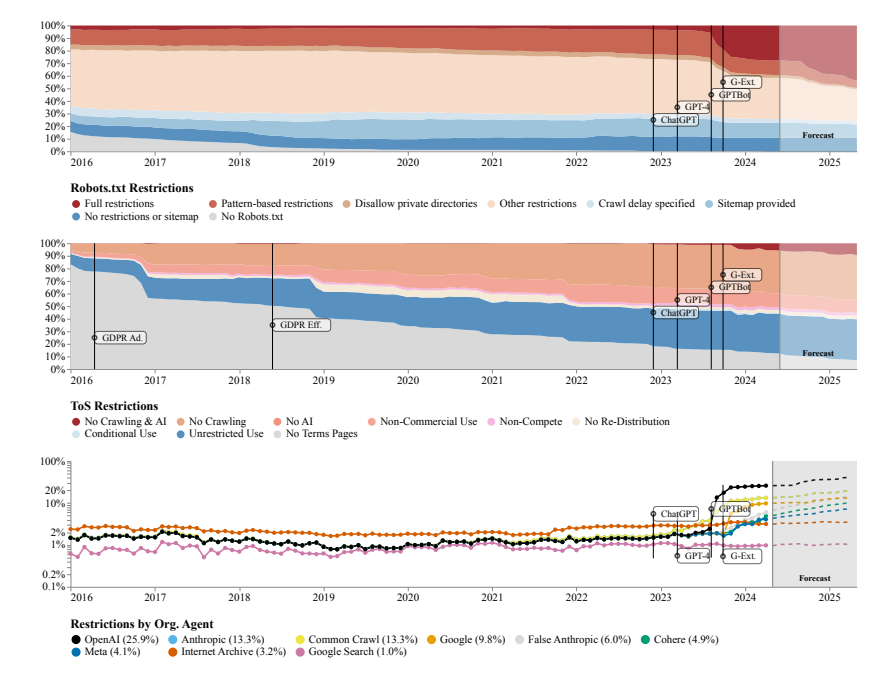
透過SARIMA模型預測,未來無論是透過robots.txt或ToS,網站對資料的限制都將持續增加。這表明,開放網路資料的取得將變得更加困難。
研究也發現,網路上爬取的資料與AI模型的訓練用途並不一致,這對模型對齊、資料收集實務以及版權都可能造成影響。
研究團隊呼籲需要更靈活的協議來反映網站所有者的意願,將有許可和不被允許的用例分開,並與服務條款同步。同時,他們希望AI開發人員能夠使用開放網路上的資料進行訓練,並希望未來的法律能支持這一點。
論文網址:https://www.dataprovenance.org/Consent_in_Crisis.pdf
這項研究對人工智慧領域的資料取得問題敲響了警鐘,也為未來AI模型的訓練與發展提出了新的挑戰。如何平衡資料取得與網站所有者權益,將成為人工智慧領域需要認真思考和解決的關鍵問題。 Downcodes小編建議關注論文,以了解更多細節。