人工智慧影像生成領域日新月異,繼Midjourney更新後,開源模型FLUX.1強勢來襲,其性能據稱超越了DALL·E3、Midjourney V6等閉源模型,以及SD3系列開源模型,引發業界廣泛關注。 Downcodes小編將帶您深入了解這款由擴散模型領域權威專家Robin Rombach打造的全新力作,以及它背後的技術創新和未來展望。
在人工智慧領域,每一天都可能發生顛覆性的變革。就在Midjourney剛進行大更新的第二天,開源影像生成領域就迎來了一匹令人矚目的黑馬——FLUX.1。這個突如其來的新玩家不僅在性能上聲稱大幅超越了DALL·E3、Midjourney V6等閉源模型,還將開源的SD3系列全線秒殺,瞬間引爆了AI圈。
讓我們先來認識FLUX.1的幕後主腦。它的創辦人Robin Rombach可不是什麼無名之輩,而是擴散模型領域的權威專家。他的代表作包括VQGAN、Taming Transformers和Latent Diffusion,曾擔任Stability AI的首席科學家,領導了全球知名的Stable Diffusion系列項目。可以說,Robin Rombach在AI圖像生成領域可謂是老司機中的老司機。
今年3月,由於Stability AI內部出現動盪,Robin選擇離開。經過四個月的沉澱,他帶著新的開源大模型平台FLUX.1重磅回歸。更令人驚訝的是,FLUX.1一亮相就獲得了由著名創投機構Andreessen Horowitz領投的3,200萬美元種子輪融資。這無疑為FLUX.1的未來發展注入了強心劑。
那麼,FLUX.1到底有什麼過人之處?首先,它基於Vision Transformer架構,採用了流程匹配訓練方法,並使用旋轉位置嵌入和並行注意層來提升模型性能和硬體利用效率。這120億參數的模型推出了三個版本:
Pro版:透過API使用,效能最強勁。
Dev版:非商用的指導蒸餾模型,繼承了Pro版的大部分性能。
Schnell版:可以商用的開源模型,效能也相當出色。
根據FLUX.1團隊的測試數據,即便是開源的Schnell版本,在文字語義還原、圖片品質、動作一致性、連貫性和多樣性等方面,也超越了Midjourney v6.0、DALL·E3(HD)和SD3-Ultra等主流模型。特別是在文字嵌入圖片方面,FLUX.1展現了明顯的優勢。
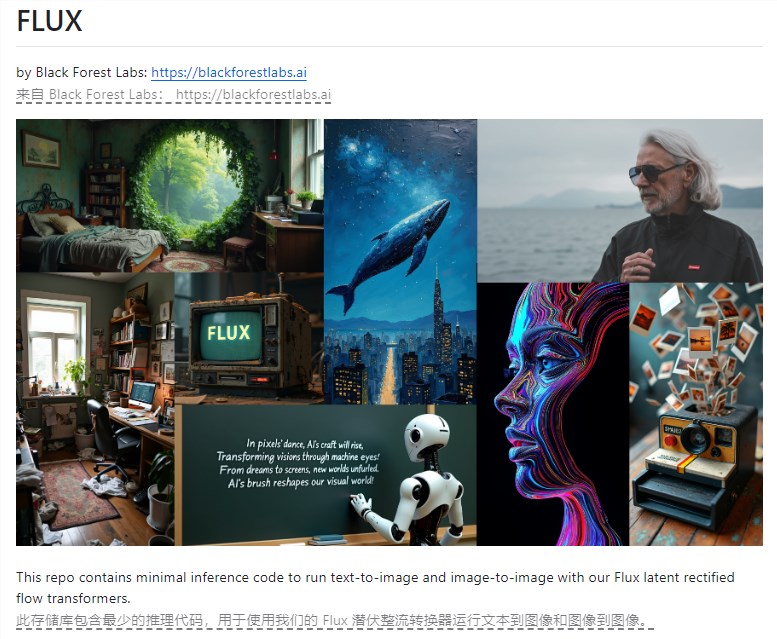
這裡,AIbase挑選了幾張官方的生成效果展示,大家可以參考一下:
真實攝影圖片
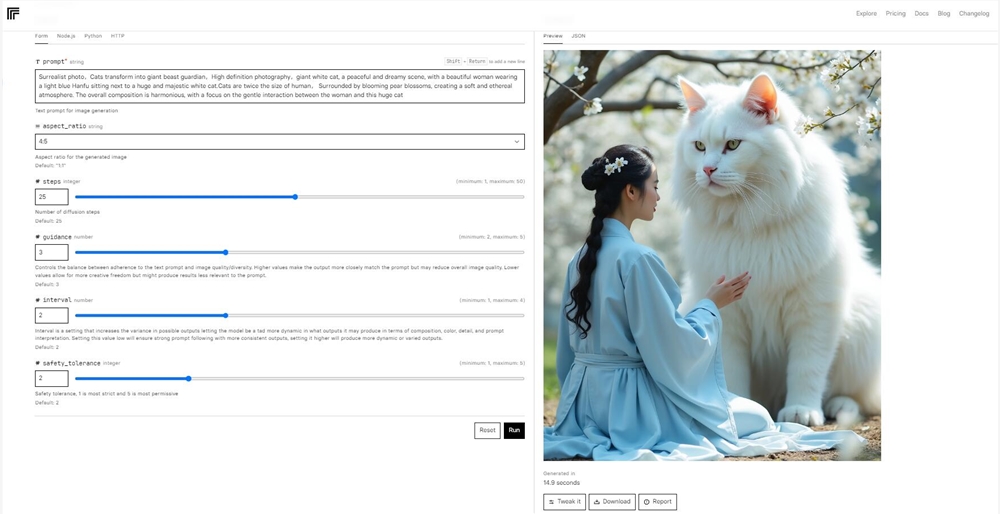
AIbase測試了一下之前的貓貓守護神,也完全沒問題,FLUX.1對提示詞的理解比較準確。
當然,FLUX.1的野心顯然不止於此。團隊表示,文生圖只是一個開始,未來他們還計劃推出文生視訊模型,挑戰Sora、Gen-3、Luma等第一線產品。
對於開發者和AI愛好者來說,FLUX.1的出現無疑是一個重大利好。 Schnell版本已經完全開源,並獲得了Comfyui的支援。如果你有36G以上的顯存,甚至可以執行t5的fp16版本。不過要注意的是,t5xxl_fp16.safetensors或clip_l.safetensors以及VAE需要單獨下載。
FLUX.1的橫空出世,不僅為開源AI影像生成領域帶來了新的希望,也為整個AI產業注入了新的活力。它的強大性能和開源特性,很可能會加速AI影像生成技術的普及和創新。對於一般用戶來說,這意味著我們可能很快就能在家用電腦上運行媲美甚至超越Midjourney的AI圖像生成模型。
專案地址:https://github.com/black-forest-labs/flux
試玩網址:https://replicate.com/black-forest-labs/flux-pro
Comfyui工作流程:https://comfyanonymous.github.io/ComfyUI_examples/flux/
總而言之,FLUX.1的出現標誌著開源AI影像生成領域進入了一個新的階段,其強大的效能和開源特性將極大地推動AI影像生成技術的普及和發展。我們期待FLUX.1在未來帶來更多驚喜!