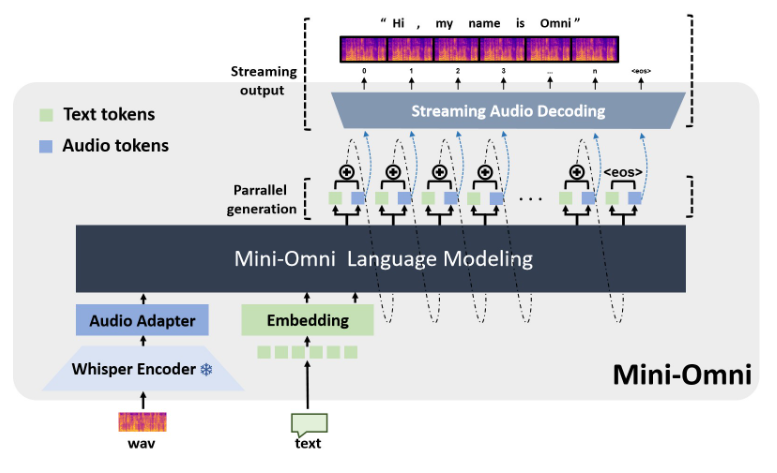
Mini-Omni,一個開源的多模態大型語言模型,正在革新語音互動技術。它整合了先進技術,實現即時語音輸入輸出,並具備邊思考邊說話的能力,帶來更自然流暢的人機互動體驗。 Mini-Omni的核心優勢在於其端對端的即時語音處理能力,無需額外配置ASR或TTS模型,即可享受流暢對話。它支援多種模態輸入並靈活轉換,適應各種複雜場景,滿足多樣化需求。
在人工智慧快速發展的今天,一款名為Mini-Omni的開源多模態大型語言模型正在引領語音互動技術的革新。這個由多個先進技術整合而成的AI系統,不僅能夠實現即時的語音輸入和輸出,還具備邊思考邊說話的獨特能力,為用戶帶來前所未有的自然互動體驗。
Mini-Omni的核心優勢在於其端對端的即時語音處理能力。使用者無需額外配置自動語音辨識(ASR)或文字轉語音(TTS)模型,就能享受流暢的語音對話。這種無縫銜接的設計大大提升了使用者體驗,使人機互動更加自然和直覺。
除了語音功能,Mini-Omni也支援文字等多種模態的輸入,並能在不同模態之間靈活轉換。這種多模態處理能力使得模型可以適應各種複雜的互動場景,滿足使用者多樣化的需求。
特別值得一提的是Mini-Omni的Any Model Can Talk功能。這項創新使得其他AI模型能夠輕鬆整合Mini-Omni的即時語音能力,大大擴展了AI應用的可能性。這不僅為開發者提供了更多選擇,也為AI技術的跨領域應用鋪平了道路。
在性能方面,Mini-Omni展現了全面的實力。它不僅在語音辨識(ASR)和語音生成(TTS)等傳統語音任務中表現出色,在TextQA、SpeechQA等需要複雜推理能力的多模態任務中也顯示出強大的潛力。這種全面的能力使得Mini-Omni能夠應付各種複雜的互動場景,從簡單的語音指令到需要深度思考的問答任務,都能游刃有餘。
Mini-Omni的技術實現融合了多個先進的AI模型和技術。它以Qwen2作為大型語言模型的基礎,利用litGPT進行訓練和推理,採用whisper進行音訊編碼,snac負責音訊解碼。這種多技術融合的方法不僅提高了模型的整體性能,也增強了其在不同場景下的適應能力。
對於開發者和研究人員來說,Mini-Omni提供了方便的使用方式。透過簡單的安裝步驟,使用者就能在本機環境中啟動Mini-Omni,並透過Streamlit和Gradio等工具進行互動式簡報。這種開放和易用的特性,為AI技術的普及和創新應用提供了有力支持。
專案網址:https://github.com/gpt-omni/mini-omni
Mini-Omni憑藉其強大的功能、便捷的使用方式以及開放的開源特性,為AI語音互動領域帶來了新的可能性,值得開發者和研究人員關注和探索。其未來發展也值得期待。