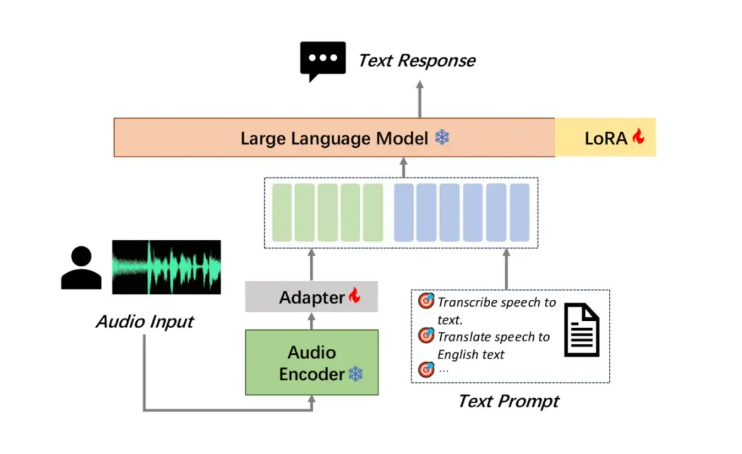
摩爾線程開源了其音頻理解大模型MooER,這是業界首個基於國產全功能GPU訓練和推理的大型開源語音模型,具有里程碑式的意義。 MooER支援中英文語音辨識和中譯英語音翻譯,展現了強大的多語言處理能力,其創新性的三部分模型結構(Encoder、Adapter和Decoder)使得模型能夠高效處理音頻並執行下游任務。目前已開源推理程式碼和基於5000小時資料訓練的模型,未來也將開源訓練程式碼和基於8萬小時資料訓練的增強版模型,這將極大推動國內外音頻AI技術的發展。
MooER在多個知名開源音訊理解大模型的對比測試中表現出色,中文字錯誤率(CER)低至4.21%,英文詞錯誤率(WER)為17.98%,尤其在中譯英測試集上的BLEU分數高達25.2,領先其他開源模型。基於8萬小時資料訓練的MooER-80k模型表現更強,CER和WER分別降至3.50%和12.66%,展現了巨大的潛力。摩爾線程此舉不僅展現了國產GPU在AI領域的強大實力,也為全球音訊AI技術發展注入了新的活力,令人期待MooER在未來能帶來更多突破。
在與多個知名開源音訊理解大模型的比較測試中,MooER-5K表現優異。在中文測驗中,其字錯誤率(CER)達到4.21%;英文測驗中,字錯誤率(WER)為17.98%,與其他頂級模型相比表現更優或相當。特別值得一提的是,在Covost2zh2en中譯英測試集上,MooER的BLEU分數高達25.2,大幅領先其他開源模型,達到了可與工業級應用媲美的水平。
更令人期待的是,基於8萬小時資料訓練的MooER-80k模型展現出更強大的效能,在中文測試集上的CER進一步降至3.50%,英文測試集上的WER也優化到12.66%,顯示了巨大的發展潛力。
摩爾線程此次開源MooER不僅展現了國產GPU在AI領域的應用實力,也為全球音訊AI技術的發展注入了新的活力。隨著更多訓練資料與程式碼的開源,業界期待MooER能在語音辨識、翻譯等領域帶來更多突破性進展,推動音訊AI技術的普及與創新應用。
網址:https://arxiv.org/pdf/2408.05101
MooER的開源,標誌著國產GPU在AI大模型領域取得了重大進展,為國內外開發者提供了寶貴的資源和平台。期待未來MooER能夠在更多應用情境中發揮作用,推動音頻AI技術的持續創新與發展。