大模型的指令調優是提升其效能的關鍵。騰訊優圖實驗室和上海交通大學合作,發布了一篇詳盡的綜述,深入探討了指令調校資料集的評估和選擇。這篇萬字長文,基於400餘篇相關文獻,從資料品質、多樣性和重要性三個維度,為大模型的指令調優提供了全面的指導,並指出了現有研究的挑戰和未來的發展方向。文章中涵蓋了多種評估方法,包括手動設計指標、基於模型的指標、GPT自動評分以及人工評價,旨在幫助研究者選擇最優的數據集,提高大模型的性能和穩定性。
隨著不斷迭代升級,大模型們變得越來越聰明,但要讓它們真正理解我們的需求,指令調優是關鍵。騰訊優圖實驗室和上海交通大學的專家們聯手,發布了一篇深入探討指令調優資料集評估與選擇的萬字綜述,為我們揭開了提升大模型性能的神秘面紗。
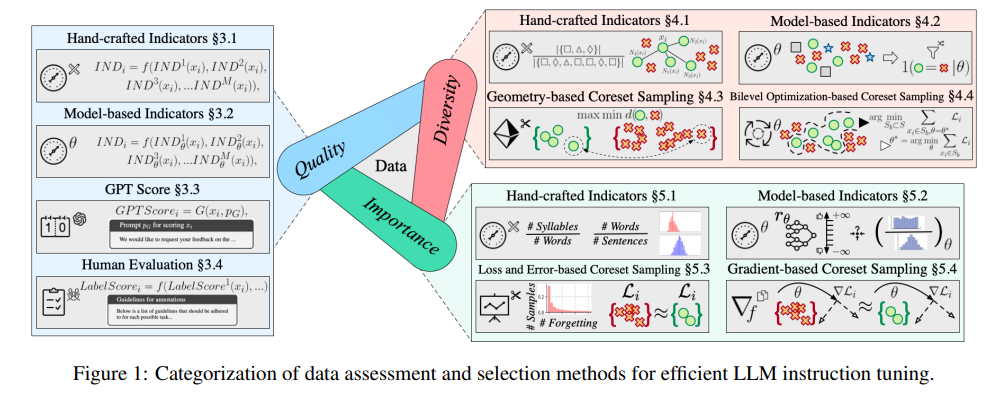
大模型們的目標是掌握自然語言處理的精髓,而指令調優則是它們學習過程中的重要一步。專家們深入分析如何評估和選擇資料集,以確保大模型在各種任務中都能表現出色。
這篇綜述不僅篇幅驚人,更涵蓋了400餘篇相關文獻,從數據品質、多樣性和重要性三個維度,為我們提供了一份詳盡的指南。
數據品質直接影響指令調優的效果。專家提出了多種評估方法,包括手工設計指標、基於模型的指標、GPT自動評分,以及不可或缺的人工評估。
多樣性評估關注的是資料集的豐富度,包括詞彙、語意以及整體資料分佈的多樣性。透過多樣化的資料集,模型能夠更好地泛化到各種場景。
重要性評估則是挑選出模型訓練最關鍵的樣本。這不僅能提高訓練效率,還能確保模型在面對複雜任務時的穩定性和準確性。
儘管目前的研究已經取得了一定的成果,但專家們也指出了存在的挑戰,例如資料選擇與模型效能之間的關聯性不強,以及缺乏統一的標準來評估指令的品質。
面向未來,專家呼籲建立專門的基準來評估指令調優模型,同時提高選擇管道的可解釋性,以適應不同的下游任務。
騰訊優圖實驗室和上海交通大學的研究,不僅為我們提供了寶貴的資源,也為大模型的發展指明了方向。隨著科技的不斷進步,我們有理由相信,大模型將變得更加智能,更好地服務人類。
論文網址:https://arxiv.org/pdf/2408.02085
這項研究為大模型指令調校提供了寶貴的指導,為未來大模型的發展奠定了堅實的基礎。 期待未來有更多類似的研究成果,推動大模型技術的持續進步,更好地服務人類。