騰訊優圖實驗室等機構開源了首個多模態大語言模型VITA,它能同時處理視頻、圖像、文本和音頻,並提供流暢的交互體驗。 VITA的出現旨在彌補現有大型語言模型在中文方言處理上的不足,基於Mixtral8×7B模型,擴展了中文詞彙量並進行了雙語指令微調,使其既精通英語,又流利使用中文。這標誌著開源社群在多模態理解和互動方面取得了重大進展。
最近,騰訊優圖實驗室等機構的研究者們推出了首個開源的多模態大語言模型VITA,它能夠同時處理視頻、圖像、文本和音頻,而且,它的交互體驗也是一流的。
VITA模型的誕生,是為了填補大型語言模型在處理中文方言方面的不足。它基於強大的Mixtral8×7B模型,擴展了中文詞彙量,進行了雙語指令微調,讓VITA不僅精通英語,還能流利地使用中文。
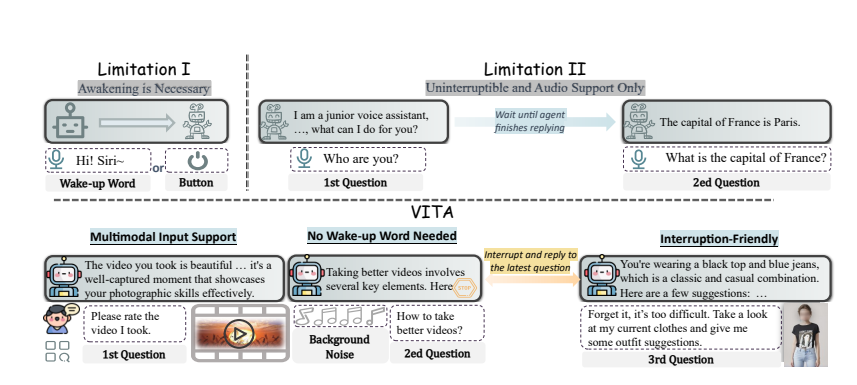
主要特點:
多模態理解:VITA能夠處理視訊、圖像、文字和音頻,這在開源模型中是前所未有的。
自然互動:無需每次都說“嘿,VITA”,它就能在你說話時隨時響應,甚至在你和別人交談時,它也能保持禮貌,不隨意插嘴。
開源先鋒:VITA是開源社群在多模態理解和互動方面邁出的重要一步,為後續研究奠定了基礎。
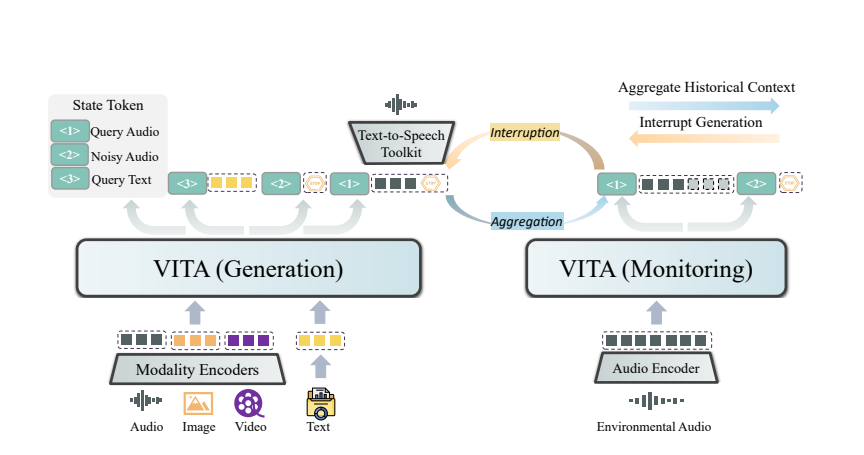
VITA的魔法來自於它的雙重模型部署。一個模型負責產生對使用者查詢的回應,另一個模型持續追蹤環境輸入,確保每一次互動都能精準、及時。
VITA不僅能聊天,還能在你健身時充當聊天夥伴,甚至在你旅遊時提供建議。它還能根據你提供的圖片或影片內容回答問題,展現出強大的實用性。
雖然VITA已經展現了巨大的潛力,但在情緒語音合成和多模態支持等方面,它仍在不斷進化。研究者們計劃讓下一代VITA能夠從視頻和文字輸入生成高品質的音頻,甚至探索同時生成高品質音頻和視頻的可能性。
VITA模型的開源,不僅是技術的勝利,更是對智慧互動方式的一次深刻革新。隨著研究的深入,我們有理由相信,VITA將為我們帶來更聰明、更人性化的互動體驗。
論文網址:https://arxiv.org/pdf/2408.05211
VITA的開源,為多模態大語言模型的發展提供了新的方向,其強大的功能和便捷的互動體驗,預示著未來人機互動方式將更加智慧和人性化。我們期待VITA在未來能有更大的突破,為人們的生活帶來更多便利。