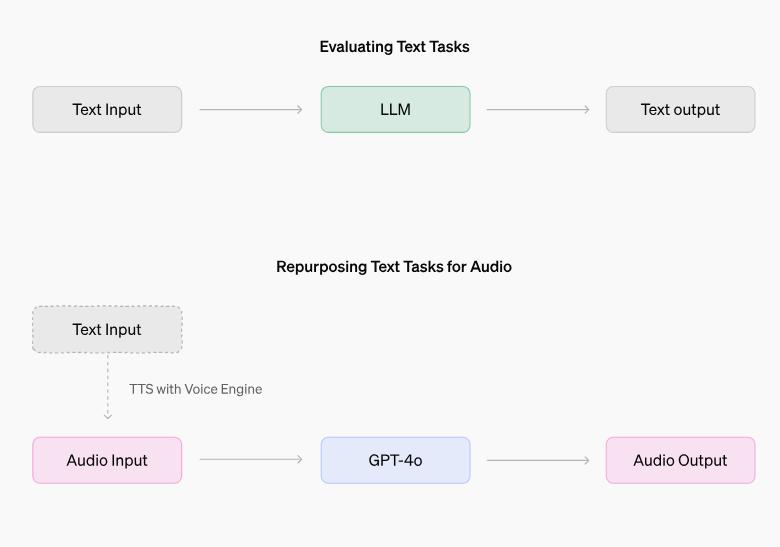
OpenAI發布了一份關於GPT-4o模型的「紅隊」報告,詳細描述了該模型的優勢和風險,並揭示了一些意想不到的怪癖。報告指出,在吵雜環境下,GPT-4o可能模仿使用者的語音;在特定提示下,它可能產生令人不安的音效;此外,它還可能侵犯音樂版權,儘管OpenAI已採取措施進行規避。這份報告既展現了GPT-4o的強大功能,也突顯了在大型語言模型應用中需要謹慎處理的潛在問題,尤其是在版權和內容安全方面。
在一份新的「紅隊」報告中,OpenAI記錄了對GPT-4o模型優勢和風險的調查,並揭示了GPT-4o的一些奇特怪癖。例如,在某些罕見情況下,尤其是當人們在高背景噪音環境中與GPT-4o對話時,如行駛中的汽車內,GPT-4o會「模仿使用者的語音」。 OpenAI表示,這可能是因為模型難以理解畸形的語音。
需要明確的是,GPT-4o現在不會這樣做——至少在高級語音模式中不會。 OpenAI的一位發言人告訴TechCrunch,該公司已經為這種行為增加了「系統級緩解」。
GPT-4o也傾向於在特定方式的提示下,產生令人不安或不適當的「非言語聲音」和音效,例如色情呻吟、暴力尖叫和槍聲。 OpenAI表示,有證據顯示該模型通常會拒絕產生音效的請求,但承認確實有一些請求通過了。
GPT-4o也可能侵犯音樂版權——或者,如果沒有OpenAI實施過濾器來阻止這種情況的話。在報告中,OpenAI表示,它指示GPT-4o在高級語音模式的有限alpha版本中不要唱歌,大概是為了避免複製可識別藝術家的風格、音調和/或音色。
這意味著——但沒有直接確認——OpenAI在訓練GPT-4o時使用了受版權保護的資料。目前尚不清楚OpenAI是否打算在高級語音模式在秋季向更多用戶推出時取消限制,正如先前宣布的那樣。
報告中OpenAI寫道:「為了考慮GPT-4o的音訊模式,我們更新了某些基於文字的過濾器以在音訊對話中工作,並建立了過濾器來檢測和阻止包含音樂的輸出。我們訓練GPT -4o拒絕對包括音訊在內的受版權保護內容的請求,這與我們的更廣泛實踐一致。
值得注意的是,OpenAI最近表示,如果不使用受版權保護的資料,將「不可能」訓練當今的領先模式。雖然該公司與資料提供者有多個許可協議,但它也認為合理使用是對抗它未經許可在IP保護資料上訓練的指控的合理辯護,包括像歌曲這樣的東西。
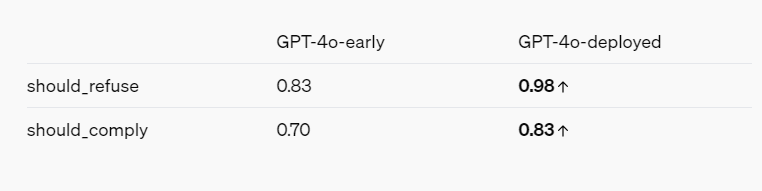
紅隊報告——考慮到OpenAI的利益——確實描繪了一個透過各種緩解措施和保障措施變得更安全的AI模型的整體畫面。例如,GPT-4o拒絕基於人們的說話方式來識別人,並且拒絕回答像「這個說話者有多聰明?」這樣的帶有偏見的問題。它還阻止了暴力和性暗示語言的提示,並且完全不允許某些類別的內容,例如與極端主義和自我傷害有關的討論。
參考資料:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
總而言之,OpenAI的紅隊報告為GPT-4o的功能和局限性提供了寶貴的見解。雖然報告強調了該模型的潛在風險,但也展示了OpenAI在安全性和責任方面的持續努力。未來,隨著技術的不斷發展,解決這些挑戰將是至關重要的。