大型語言模型(LLMs)在長文本理解方面面臨挑戰,其上下文視窗大小限制了其處理能力。為解決此問題,研究者開發了LooGLE基準測試,用於評估LLMs的長語境理解能力。 LooGLE包含776篇2022年後發布的超長文件(平均19.3k單字)和6448個測試實例,涵蓋多個領域,旨在更全面地評估模型對長文本的理解和處理能力。該基準測試對現有LLMs的性能進行了評估,並為未來模型的研發提供了寶貴的參考。
在自然語言處理領域,長語境理解一直是個挑戰。儘管大型語言模型(LLMs)在多種語言任務上表現出色,但它們在處理超出其上下文視窗大小的文字時常常受限。為了克服這個限制,研究者一直在努力提升LLMs對長文本的理解能力,這不僅對於學術研究具有重要意義,對於現實世界的應用場景,如特定領域的知識理解、長對話生成、長故事或程式碼生成等,同樣至關重要。
在這項研究中,作者們提出了一個新的基準測試——LooGLE(Long Context Generic Language Evaluation),專為評估LLMs的長語境理解能力而設計。這個基準測試包含了776篇2022年之後的超長文檔,每篇文檔平均包含19.3k個單詞,並且有6448個測試實例,涵蓋了多個領域,如學術、歷史、體育、政治、藝術、事件和娛樂等。
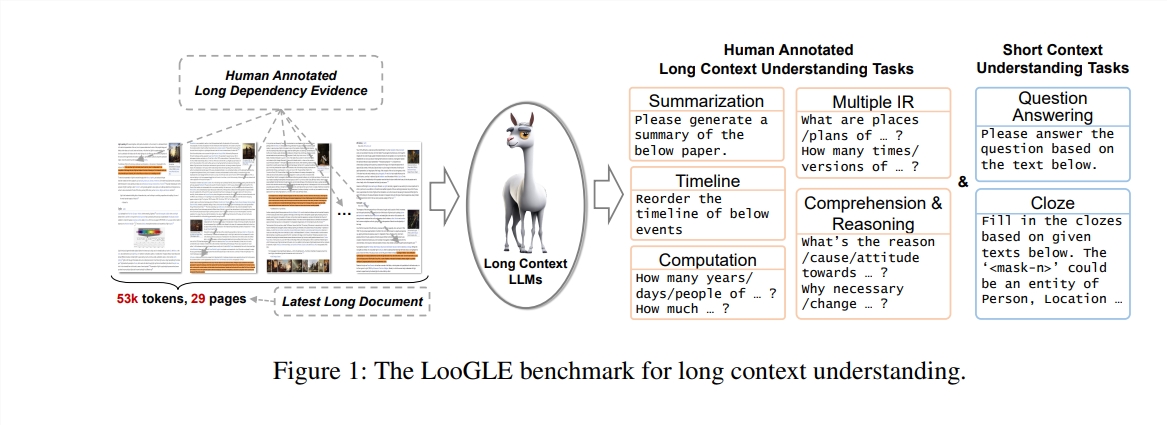
LooGLE的特點
超長的真實文件:ooGLE中的文件長度遠遠超過LLMs的上下文視窗大小,這要求模型能夠記憶和理解更長的文字。
手動設計的長短依賴任務:基準測試包含了7個主要任務,包括短依賴和長依賴任務,以評估LLMs對長短依賴內容的理解能力。
相對新穎的文檔:所有文件都是2022年之後發布的,這確保了大多數現代LLMs在預訓練期間沒有接觸過這些文檔,從而更準確地評估它們的語境學習能力。
跨領域通用資料:基準測試的資料來自流行的開源文檔,如arXiv論文、維基百科文章、電影和電視劇本等。
研究者們對8種最先進的LLMs進行了全面評估,結果揭示了以下關鍵發現:
商業模型在性能上超過了開源模型。
LLMs在短依賴任務上表現出色,但在更複雜的長依賴任務上有挑戰。
基於情境學習和思維鏈的方法在長語境理解上僅提供了有限的改進。
基於檢索的技術在短問題回答中顯示出顯著的優勢,而透過優化的Transformer架構或位置編碼來擴展上下文視窗長度的策略對長語境理解的影響有限。
LooGLE基準測試不僅為評估長語境LLMs提供了一個系統和全面的評價方案,而且為未來開發具有「真正長語境理解」能力的模型提供了指導。所有評估代碼已在GitHub上發布,供研究社群參考和使用。
論文網址:https://arxiv.org/pdf/2311.04939
代碼位址:https://github.com/bigai-nlco/LooGLE
LooGLE基準測試為評估和改進LLMs的長文本理解能力提供了重要工具,其研究結果對推動自然語言處理領域的發展具有重要意義。 研究者提出的改進方向值得關注,相信未來會有更多更強大的LLMs出現,更好地處理長文本。