蘋果公司攜手華盛頓大學等機構,開源發布了名為DCLM的強大語言模型,其參數規模達7億,訓練資料量更是驚人地達到了2.5萬億個資料令牌。 DCLM不僅是一個高效的語言模型,更重要的是它提供了一個名為「資料集競爭」(DataComp)的工具,用於優化語言模型的資料集。這項創新不僅提升了模型效能,也為語言模型研究提供了新的方法和標準,值得關注。
最近,蘋果公司的人工智慧團隊和華盛頓大學等多家機構合作,推出一款名為DCLM的開源語言模式。這款模型的參數達7億,並且在訓練過程中使用了多達2.5兆個資料令牌,幫助我們更好地理解和生成語言。
那麼,什麼是語言模型呢?簡單來說,它是一種可以分析和生成語言的程序,能夠幫助我們完成各種任務,例如翻譯、文本生成和情感分析。為了讓這些模型表現得更好,我們需要優質的資料集。然而,要取得和整理這些數據並不是一件容易的事,因為我們需要過濾掉無關的或有害的內容,並去除重複的資訊。
為了因應這個挑戰,蘋果的研究團隊推出了「資料集競賽」(DataComp for Language Models,簡稱DCLM),這是一個用於語言模型的資料集最佳化工具。他們最近在Hugging Face 平台上開源了DCIM 模型和資料集。開源版本包括DCLM-7B、DCLM-1B、dclm-7b-it、DCLM-7B-8k、dclm-baseline-1.0和dclm-baseline-1.0-parquet,研究人員可以透過這個平台進行大量實驗,找到最有效的資料整理策略。
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
DCLM 的核心優勢在於它的結構化工作流程。研究人員可以根據需要選擇不同規模的模型,從4.12億到7億參數不等,同時還可以試驗不同的資料整理方法,例如去重和過濾。透過這些系統化的實驗,研究人員可以清楚地評估不同資料集的品質。這不僅為未來的研究奠定了基礎,也幫助我們理解如何透過改善資料集來提升模型的表現。
例如,利用DCLM 建立的基準資料集,研究團隊訓練了一個7億參數的語言模型,竟然在MMLU 基準測試中取得了64% 的5-shot 準確率!這相較於之前的最高水平提高了6.6個百分點,使用的運算資源減少了40%。 DCLM 基準模型的表現也與Mistral-7B-v0.3和Llama38B 相當,而後兩者所需的計算資源則多得多。
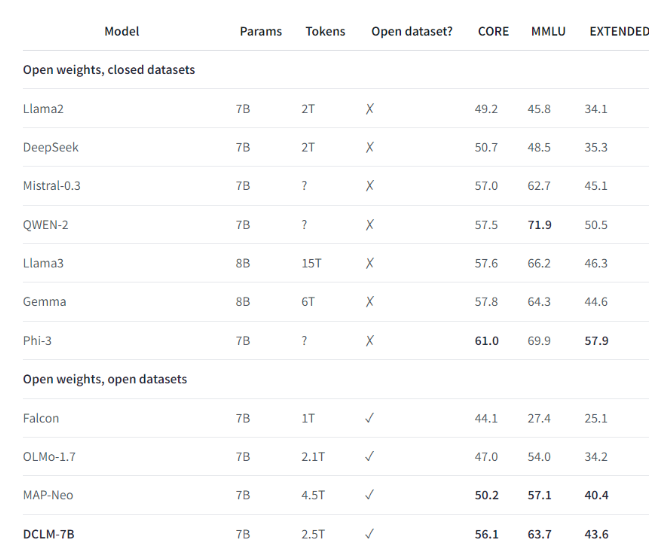
DCLM 的推出為語言模型的研究提供了一個新的標桿,幫助科學家系統地提升模型的效能,同時降低了所需的運算資源。
劃重點:
1️⃣ 蘋果AI 與多家機構合作推出DCLM,創造了一個強大的開源語言模式。
2️⃣ DCLM 提供標準化的資料集最佳化工具,幫助研究人員進行有效實驗。
3️⃣ 新模型在重要測試中取得了顯著進展,同時降低了計算資源的需求。
總而言之,DCLM 的開源為語言模型研究領域注入新的活力,其高效的模型和資料集優化工具有望推動該領域更快發展,並促進更強大、更有效率的語言模型的誕生。未來,期待DCLM能帶來更多令人驚訝的研究成果。