微軟研究人員發布了一個名為Auto Evol-Instruct的全新AI框架,該框架能夠自動進化指導資料集,無需任何人工幹預。這對於提升大型語言模型(LLMs)遵循複雜指令的能力具有重大意義。傳統的進化方法依賴人工設計的規則,效率低且難以適應新任務。而Auto Evol-Instruct則透過LLMs自動分析指令,自主設計和最佳化演化規則,實現了自動化和高效的演進過程,大大提升了資料集的複雜性和多樣性。
最近,微軟的研究人員提出了一個名為Auto Evol-Instruct 的全新AI 框架,這個框架可以自動演進指導資料集,無需任何人為幹預。
在人工智慧領域,大型語言模型(LLMs)的發展至關重要,尤其是在提高這些模型遵循詳細指令的能力方面。研究人員一直在探索如何改進用於訓練LLMs 的資料集,以提高模型的效能和適應性。
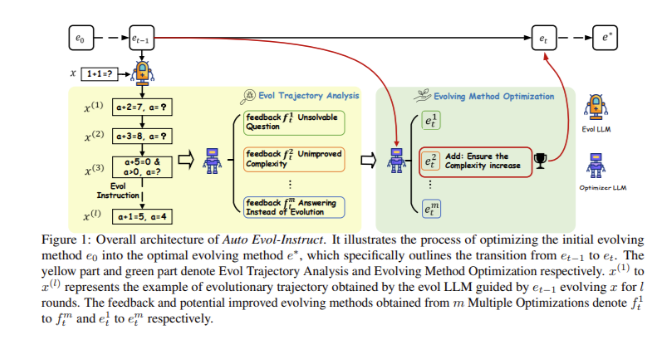
傳統的演進方法如Evol-Instruct依賴人類專家指定的演進規則,這不僅昂貴耗時,而且在適應新任務時需要重新設計方法。相較之下,Auto Evol-Instruct透過先使用LLMs分析輸入指令,並自主設計演進規則的初始方法,實現了自動化演進過程。隨後,透過優化器LLMs對演進方法進行迭代優化,識別並解決演進過程中的問題,確保最終的演進指令複雜性和穩定性。
Auto Evol-Instruct 透過自動分析輸入指令並制定演進規則,利用LLMs 設計演進方法,從而提高資料集的複雜性和多樣性。
在效能評估方面,Auto Evol-Instruct在多個基準測試中表現出色。例如,僅使用10K個演進的ShareGPT數據對Mixtral-8x7B進行微調,框架在MT-Bench上達到了8.09分,在AlpacaEval上達到了91.4分,超過了GPT-3.5-Turbo和WizardLM-70B,並與Claude2.0相當。
此外,透過僅使用7K個演進的GSM8K訓練數據,框架在GSM8K上達到了82.49分,在程式碼生成方面,透過使用20K個演進的Code Alpaca對DeepSeek-Coder-Base-33B進行微調,框架在HumanEval上達到了77.4分,超過了其他競爭模型。
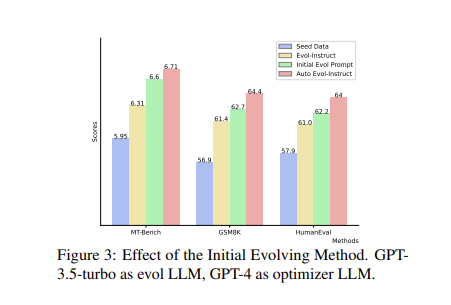
可見,這個全新的框架在多個基準測試中表現出色,包括MT-Bench、AlpacaEval、GSM8K 和HumanEval,展現出其在提高指令遵循、數學推理和代碼生成能力方面的潛力。
論文網址:https://arxiv.org/abs/2406.00770
劃重點:
Auto Evol-Instruct 是一個全自動的AI 框架,能夠自動分析和演進指導資料集,無需人為介入。
框架透過優化演進方法,有效提高了資料集的複雜性和多樣性,從而增強了LLMs 在各種任務中的效能和適應性。
Auto Evol-Instruct 的研究結果表明,透過自動化演進來指導資料集的方法。
Auto Evol-Instruct框架的出現,標誌著LLMs訓練資料進化方法的重大革新,其自動化、高效的特點將極大推動LLMs的發展,為建立更強大、更適應性強的AI模型提供有力支撐。 相關論文已發布,有興趣的讀者可以深入研究。